掌握 Python 爬虫 requests 处理 Cookies 的秘诀
在当今数字化的时代,数据的获取和处理变得越来越重要,Python 爬虫作为一种强大的数据采集工具,其在众多领域都发挥着关键作用,而在 Python 爬虫中,requests 库处理 Cookies 的能力更是决定了爬虫的效率和稳定性。
要理解 requests 如何处理 Cookies,首先得明白 Cookies 的概念和作用,Cookies 是服务器发送到用户浏览器并保存在本地的一小块数据,它用于在后续的请求中携带特定的信息,以实现用户身份验证、会话跟踪等功能。
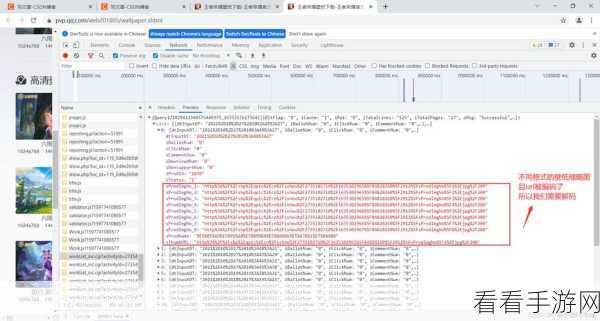
我们看看 requests 库提供的处理 Cookies 的方法,最简单的方式就是在发送请求时自动处理 Cookies,requests 会自动保存和发送服务器返回的 Cookies,使得后续的请求能够保持会话状态。
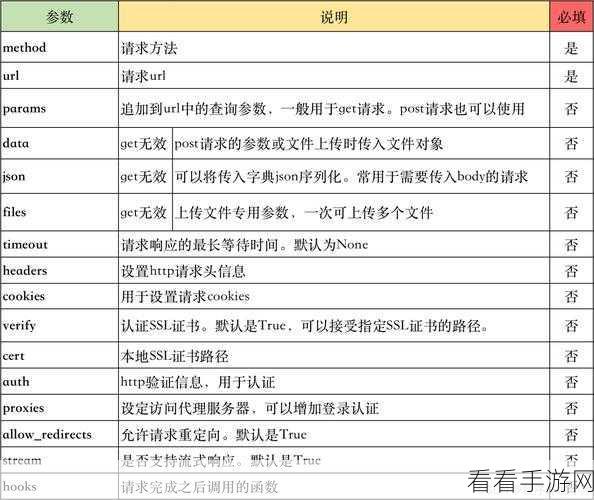
如果需要手动操作 Cookies,requests 也提供了相应的接口,可以通过 requests.get() 或 requests.post() 方法的 cookies 参数来设置自定义的 Cookies。
还可以获取响应中的 Cookies 信息,通过 response.cookies 属性,可以获取到服务器返回的 Cookies 字典,从而进行进一步的处理和分析。
在实际应用中,处理 Cookies 可能会遇到一些问题,Cookies 过期、Cookies 被服务器拒绝等,针对这些情况,需要根据具体的错误信息进行相应的处理和调整。
熟练掌握 Python 爬虫 requests 处理 Cookies 的方法,能够让我们在数据采集的道路上更加得心应手,不断实践和探索,才能更好地运用这一强大的工具。
文章参考来源:Python 官方文档及相关技术论坛。
