探索 Flink 与 Hive 集成的奇妙之旅
在当今的数据处理领域,Flink 和 Hive 的集成成为了众多开发者关注的焦点,实现 Flink 与 Hive 的集成,能够为数据处理带来更高效、更灵活的解决方案。
要成功实现 Flink 集成 Hive,首先需要明确两者的特点和优势,Flink 作为一款优秀的流处理框架,具备出色的实时处理能力;而 Hive 则在大规模数据的存储和分析方面表现卓越。
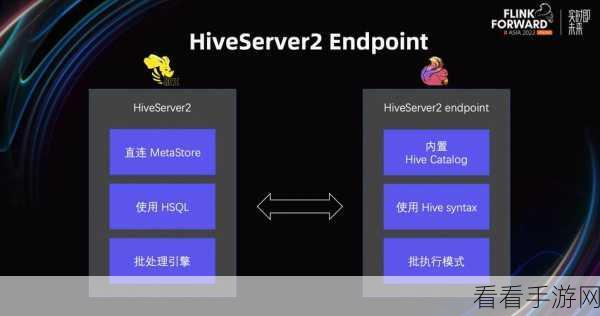
需要准备好相应的环境,确保安装了正确版本的 Flink 和 Hive,并对其进行合理的配置,这包括设置相关的环境变量、配置文件等,以保证两者能够正常通信和协同工作。
要了解数据的传输和转换方式,在 Flink 中,可以使用特定的 Connector 来实现与 Hive 的数据交互,通过这些 Connector,能够将 Flink 中的数据写入 Hive 表,或者从 Hive 表中读取数据进行处理。
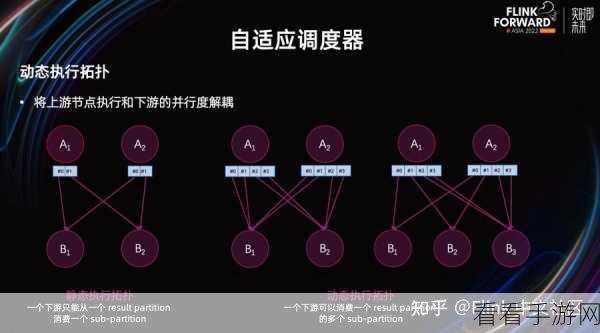
还需要注意数据的一致性和准确性,在集成过程中,可能会遇到数据类型不匹配、数据丢失等问题,需要进行严格的数据校验和错误处理,以确保数据的质量。
对集成后的系统进行性能优化也是至关重要的,通过调整参数、优化算法等方式,提高数据处理的效率和速度,满足实际业务的需求。
实现 Flink 集成 Hive 并非一蹴而就,需要对两者有深入的了解,并在实践中不断摸索和优化。
文章参考来源:相关技术文档和实践经验总结。
