Python 和 JS 爬虫应对浏览器插件的巧妙策略
在当今数字化时代,爬虫技术的应用愈发广泛,而 Python 和 JS 爬虫在处理浏览器插件时面临着诸多挑战。
要深入理解 Python 和 JS 爬虫如何处理浏览器插件,就得先明晰浏览器插件的工作原理和其可能对爬虫造成的影响,浏览器插件能够增强浏览器的功能,但也可能会干扰爬虫的正常运行,比如改变网页的结构、添加额外的请求或限制访问权限。
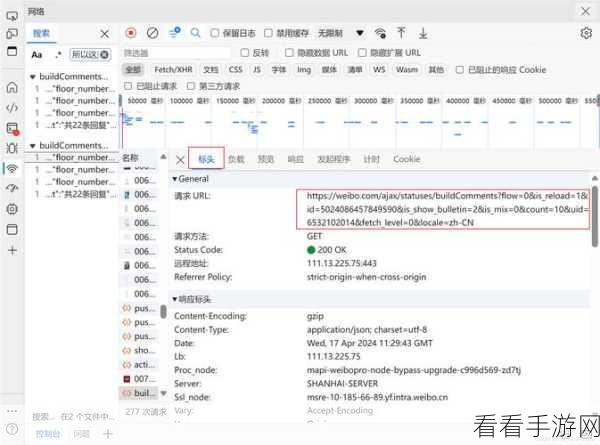
探讨 Python 爬虫处理浏览器插件的方法,一种常见的方式是通过模拟浏览器行为来绕过插件的限制,可以使用诸如 Selenium 这样的工具,它能够模拟真实的浏览器操作,从而有效地应对插件带来的变化。
JS 爬虫在处理浏览器插件时也有自己的一套策略,通过分析插件生成的 JavaScript 代码,找出其中的规律和关键部分,然后针对性地进行处理。
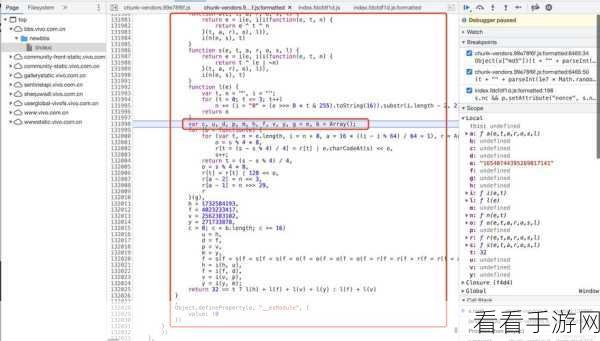
无论是 Python 还是 JS 爬虫,都需要时刻关注浏览器插件的更新和变化,及时调整爬虫的策略,以适应新的情况。
在实际应用中,还需要注意法律法规和道德规范,确保爬虫的使用是合法合规的。
Python 和 JS 爬虫处理浏览器插件需要综合运用多种技术和策略,不断探索和实践,才能在复杂的网络环境中顺利获取所需数据。
文章参考来源:相关技术论坛及专业书籍。
