探秘 Kafka 单节点的数据分区秘籍
Kafka 作为一种强大的分布式消息系统,其单节点的数据分区策略至关重要,在实际应用中,了解并掌握 Kafka 单节点如何进行数据分区,对于优化系统性能和数据处理效率有着关键作用。
Kafka 单节点的数据分区并非简单的操作,它涉及到一系列复杂的机制和策略,分区的数量需要根据具体的业务需求和数据量来合理设定,过少的分区可能导致数据处理不均衡,而过多的分区则可能增加系统的管理和维护成本。
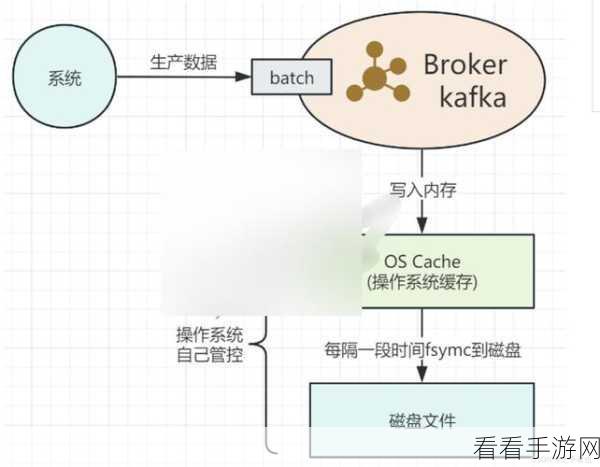
数据的分配方式也是一个重要的考量因素,Kafka 通常会根据消息的键值或者特定的算法来将数据均匀地分布到各个分区中,以确保数据的负载均衡和高效处理。
分区的副本策略也不能忽视,通过设置适当的副本数量,可以提高数据的可用性和容错性,避免因单点故障导致数据丢失或不可用。
在进行数据分区时,还需要考虑到网络带宽、存储容量以及服务器性能等硬件资源的限制,只有充分结合这些因素,才能制定出最适合当前环境的分区方案。
深入理解和掌握 Kafka 单节点的数据分区,需要综合考虑多方面的因素,并结合实际的业务场景进行不断的优化和调整,才能充分发挥 Kafka 的优势,实现高效的数据处理和传输。
文章参考来源:相关技术文档及实践经验总结。
