掌握秘籍!轻松编写 VSCode Python 爬虫
Python 爬虫编写一直是众多开发者关注的焦点,而利用 VSCode 来实现更是备受青睐,在这篇攻略中,将为您详细解析如何利用 VSCode 编写 Python 爬虫,助您在数据获取的道路上畅通无阻。
要成功编写 VSCode Python 爬虫,第一步得明确需求,清楚自己想要获取什么样的数据,是网页文本、图片,还是特定格式的文件等,只有明确了目标,后续的编写工作才能有的放矢。
接下来就是环境搭建,确保您的电脑已经安装了 Python 环境和 VSCode 编辑器,还需要安装一些必要的库,requests、beautifulsoup4 等,这些库能为爬虫编写提供强大的支持。
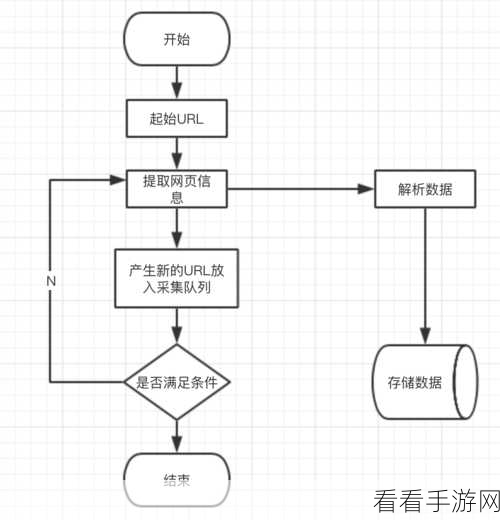
在代码编写环节,需要注重逻辑和语法的准确性,首先定义好请求的 URL,然后使用 requests 库发送请求获取网页内容,获取到内容后,再利用 beautifulsoup4 库对网页进行解析,提取出所需的数据。
还得注意反爬虫机制,许多网站都设置了反爬虫措施,如果不加以注意,可能会导致您的爬虫被封禁,在编写过程中,要合理设置请求头,模拟正常的用户访问行为。
进行测试和优化,编写完成后,要对爬虫进行多次测试,查看是否能稳定获取到所需数据,如果出现问题,及时检查代码,优化逻辑和参数。
编写 VSCode Python 爬虫需要耐心和细心,掌握好每个环节,您就能轻松获取到有价值的数据。
参考来源:Python 官方文档、相关技术论坛及个人实践经验。
