Flink 集成 Hive 能否应对海量大数据?
在当今数字化时代,数据处理的规模和复杂性不断增加,如何高效地处理大数据成为了众多企业和开发者关注的焦点,Flink 集成 Hive 这一组合在大数据处理领域备受瞩目。
Flink 作为一款强大的流处理框架,具有出色的实时处理能力和高并发特性,而 Hive 则是基于 Hadoop 的数据仓库工具,擅长处理大规模的离线数据,将两者集成起来,是否真的能够应对海量大数据的处理需求呢?
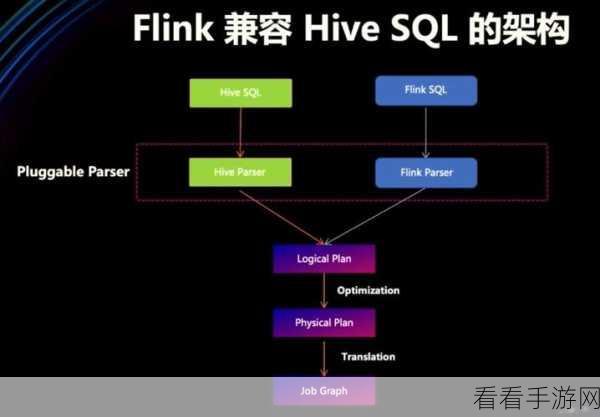
要回答这个问题,我们需要从多个方面进行分析,从性能角度来看,Flink 集成 Hive 可以充分发挥 Flink 的实时处理优势,同时借助 Hive 的大规模数据存储和处理能力,实现对海量数据的高效处理,在一些实时数据监控和分析的场景中,通过 Flink 实时获取数据,并将其与 Hive 中的历史数据进行关联和分析,可以快速得出有价值的结论。
在数据一致性方面,Flink 集成 Hive 也能够提供较好的保障,Flink 可以确保数据的实时准确性,而 Hive 则可以保证数据的一致性和完整性,通过合理的配置和优化,可以避免数据丢失和错误的情况发生。
从扩展性角度考虑,Flink 集成 Hive 具有良好的可扩展性,随着数据量的不断增长和业务需求的变化,可以灵活地增加计算资源和存储资源,以满足不断增加的处理需求。
Flink 集成 Hive 也并非完美无缺,在实际应用中,可能会遇到一些技术挑战和问题,数据格式的转换、系统配置的复杂性以及性能调优等方面,都需要开发者具备丰富的经验和技术能力。
Flink 集成 Hive 在处理大数据量方面具有很大的潜力和优势,但也需要在实际应用中根据具体的业务需求和场景进行合理的配置和优化,只有这样,才能充分发挥其强大的功能,为企业和开发者带来真正的价值。
参考来源:行业技术论坛及相关技术文档。
仅供参考,您可以根据实际需求进行调整和修改。
