深度解析,Hive Parquet 各版本的显著差异
Hive Parquet 是一款在数据处理领域备受关注的技术,在不同版本中,它展现出了多样的特点和变化。
Hive Parquet 不同版本间的差异体现在多个方面,首先是存储格式的优化,早期版本可能在数据压缩和编码方式上相对简单,导致存储空间的浪费和读取效率的低下,而较新的版本则采用了更高效的压缩算法和编码策略,显著减少了数据存储量,并提高了读取速度。

性能的提升,随着数据量的不断增长,新版本对查询性能进行了重点优化,通过改进索引结构、优化执行计划等手段,使得大规模数据的查询和处理更加迅速和准确。
再者是功能的丰富,不同版本中,Hive Parquet 不断增加新的功能特性,以满足用户日益复杂的需求,支持更多的数据类型、提供更灵活的分区方式等。
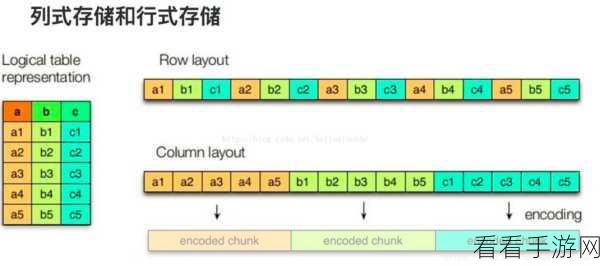
兼容性也是版本差异的一个重要方面,新版本往往需要考虑与其他相关技术和工具的兼容性,以确保在整个数据处理生态系统中能够顺畅地协同工作。
在实际应用中,了解 Hive Parquet 不同版本的差异对于选择合适的版本以及优化数据处理流程至关重要,用户可以根据自身的业务需求、数据规模和技术环境,综合评估各个版本的特点,从而做出明智的决策。
参考来源:相关技术文档及行业研究报告。
仅供参考,您可以根据实际需求进行调整。
