Python 多线程爬虫重试机制的奥秘与实战攻略
在当今数字化时代,数据的获取变得至关重要,而 Python 多线程爬虫技术则成为了许多开发者的得力工具,在爬虫过程中,难免会遇到各种问题导致请求失败,此时重试机制就显得尤为重要。
Python 多线程爬虫的重试机制是确保数据采集完整性和稳定性的关键,当爬虫在发送请求时遭遇网络故障、服务器响应错误或者其他意外情况时,重试机制能够自动重新发送请求,以提高获取数据的成功率。
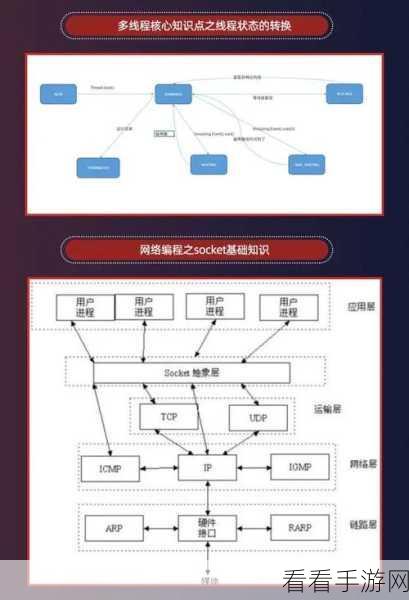
要实现有效的重试机制,需要考虑多个因素,首先是设置合理的重试次数和重试间隔,重试次数过多可能会导致资源浪费和被目标网站封禁,过少则可能无法获取到所需数据,重试间隔的设置也需要谨慎,太短可能会对目标服务器造成过大压力,太长则可能影响爬虫的效率。
需要对不同的错误类型进行分类处理,对于网络连接超时的错误,可以适当增加重试次数;而对于服务器返回的 403 禁止访问等错误,则需要重新评估爬虫策略,可能需要更换 IP 或者降低访问频率。
在实现重试机制时,还需要考虑日志记录和监控,通过记录每次重试的相关信息,如错误类型、重试时间等,可以方便后续的分析和优化,实时监控爬虫的运行状态,及时发现和处理异常情况。
掌握 Python 多线程爬虫的重试机制,不仅能够提高数据采集的效率和质量,还能够避免不必要的麻烦和风险,在实际应用中,开发者需要根据具体的需求和场景,灵活调整重试策略,以达到最佳的效果。
参考来源:相关技术文档和实践经验总结。
