Hive Colease 并行处理能力大揭秘
Hive Colease 作为一款备受关注的技术,其并行处理能力一直是众多开发者和用户关心的焦点,Hive Colease 到底能否实现并行处理呢?
要探究 Hive Colease 的并行处理能力,我们需要先了解其工作原理,Hive Colease 是基于分布式计算框架构建的,通过将任务分解并分配到多个节点上同时执行,从而实现高效的数据处理。
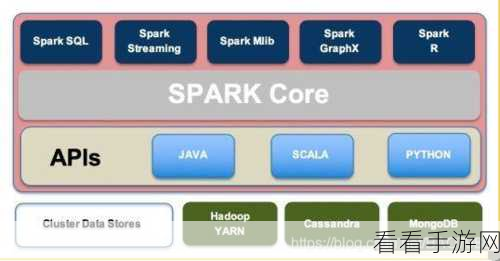
在实际应用中,Hive Colease 的并行处理效果受到多种因素的影响,数据的分布情况、计算资源的配置以及任务的复杂度等,都会对其并行处理能力产生重要作用。
当处理大规模的数据集时,如果数据分布不均匀,可能会导致某些节点负载过重,从而影响整体的并行处理效率,合理的数据分区和优化策略就显得尤为重要。
计算资源的充足与否也直接关系到 Hive Colease 的并行处理性能,如果硬件配置不足,无法满足并行处理所需的计算和存储要求,那么其效果也会大打折扣。
为了充分发挥 Hive Colease 的并行处理优势,开发者和使用者需要根据具体的业务需求和系统环境,进行针对性的优化和调整。
Hive Colease 在理论上具备实现并行处理的能力,但要在实际应用中获得理想的效果,还需要综合考虑各种因素,并采取有效的优化措施。
文章参考来源:相关技术文档及行业研究报告。
