Python 可视化爬虫分布式部署秘籍大揭秘
Python 可视化爬虫的分布式部署是一项具有挑战性但又充满魅力的技术,在当今数字化的时代,数据的获取和处理对于许多行业来说至关重要,掌握 Python 可视化爬虫的分布式部署,能够极大地提高数据采集的效率和规模。
要实现 Python 可视化爬虫的分布式部署,首先需要明确其目标和需求,不同的应用场景对爬虫的性能、准确性和稳定性有着不同的要求,在电商领域,需要快速获取大量商品信息;而在金融领域,则更注重数据的准确性和安全性。
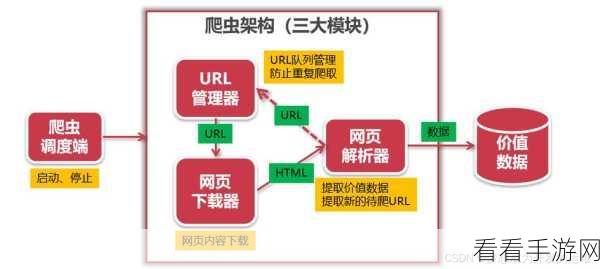
选择合适的技术框架和工具是关键,目前,有许多优秀的开源框架可供选择,如 Scrapy、PySpider 等,这些框架提供了丰富的功能和接口,能够帮助开发者快速搭建分布式爬虫系统。
在部署过程中,合理的任务分配和调度策略不可或缺,通过将爬虫任务分解为多个子任务,并分配到不同的节点上执行,可以充分利用分布式系统的计算资源,提高爬虫的效率。

数据存储和处理也是需要重点关注的环节,要确保采集到的数据能够被有效地存储和管理,以便后续的分析和应用。
还需要考虑系统的监控和容错机制,实时监控爬虫系统的运行状态,及时发现并处理异常情况,保证系统的稳定性和可靠性。
Python 可视化爬虫的分布式部署需要综合考虑多个方面的因素,从目标需求的明确到技术框架的选择,再到任务分配、数据处理以及系统监控等,只有在各个环节都做到精心设计和优化,才能打造出高效、稳定的分布式爬虫系统,为数据采集和处理工作提供有力的支持。
参考来源:相关技术文档及行业经验分享。
仅供参考,您可以根据实际需求进行调整和修改。
