深入探究,Spark SortBy 性能与数据量增长的关系奥秘
Spark SortBy 是大数据处理中一个重要的操作,其性能表现与数据量的增长有着密切的关联。
当我们在处理大量数据时,Spark SortBy 的性能变化成为了一个关键问题,数据量的不断增加,会对其性能产生多方面的影响。
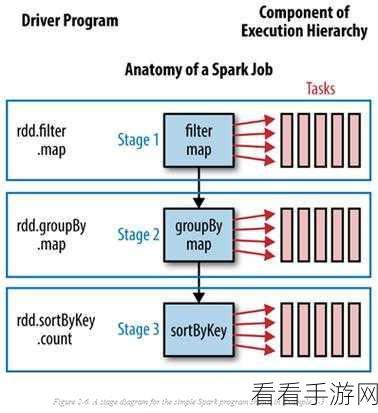
随着数据量的上升,计算资源的需求也会相应提高,这包括内存的占用、CPU 的运算时间等,如果系统的硬件配置无法跟上数据量的增长速度,那么就可能出现性能瓶颈,导致排序操作的时间大幅增加。
数据的分布特征也会影响 Spark SortBy 的性能,如果数据的分布较为均匀,那么排序的效率可能相对较高;但如果数据存在严重的倾斜,部分分区的数据量过大,就会使得整个排序过程变得不均衡,从而影响整体性能。
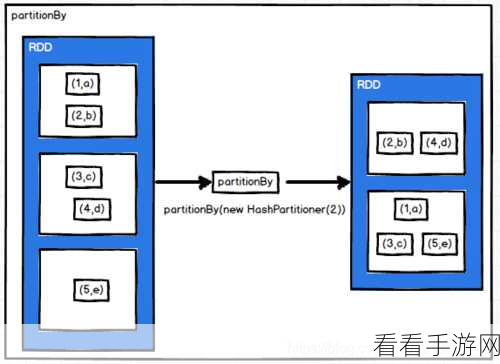
算法的优化和参数的调整对于 Spark SortBy 的性能提升也至关重要,合理设置分区数量、缓存策略等参数,可以在一定程度上改善性能。
为了更好地评估 Spark SortBy 的性能,我们进行了一系列的实验,通过逐步增加数据量,并记录不同数据量下的排序时间和资源消耗,得出了一些有价值的结论。
在实际应用中,了解 Spark SortBy 性能与数据量增长的关系,能够帮助我们更有效地规划和优化大数据处理任务,提高系统的整体性能和效率。
文章参考来源:相关技术文档及实验数据整理。
