Hive Hash 能否保障数据完整性?深度解析与攻略
Hive Hash 是当前数据处理领域备受关注的技术,众多开发者和使用者都在思考它能否切实提高数据的完整性,要弄清楚这个问题,我们需要从多个方面进行深入探讨。
Hive Hash 是一种在大数据处理中常用的哈希算法,其设计初衷就是为了优化数据的存储和检索,提高数据处理的效率,对于数据完整性的保障,不能仅仅依赖于算法本身的特性。
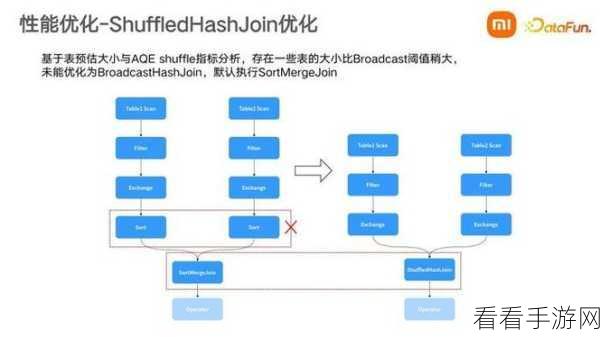
影响 Hive Hash 对数据完整性作用的因素众多,首先是数据输入的质量,如果输入的数据本身存在错误或缺失,那么即使 Hive Hash 算法再精妙,也难以保证最终数据的完整性,系统的配置和环境也至关重要,不同的硬件设施、软件版本以及网络状况,都可能对 Hive Hash 的运行效果产生影响。
在实际应用中,要充分发挥 Hive Hash 对数据完整性的保障作用,需要采取一系列有效的措施,要对输入数据进行严格的筛选和校验,确保数据的准确性和完整性,要优化系统配置,为 Hive Hash 的运行提供稳定、高效的环境。
定期对数据进行检测和修复也是必不可少的,通过建立有效的监控机制,及时发现数据完整性方面的问题,并采取相应的修复措施,能够最大程度地保障数据的可靠性。
Hive Hash 在提高数据完整性方面具有一定的潜力,但需要综合考虑多方面的因素,并采取科学合理的措施,才能充分发挥其作用,为数据处理提供更可靠的保障。
参考来源:相关技术文档及行业研究报告。
仅供参考,您可以根据实际需求进行调整和修改。
