掌握 Hive SQL 分组统计秘籍,提升数据处理能力
在当今数字化时代,数据处理成为了众多领域的关键环节,Hive SQL 作为一种强大的数据处理工具,其分组统计功能更是备受关注,让我们一同深入探索 Hive SQL 分组统计的实现方法,为您的数据处理之路增添助力。
Hive SQL 中的分组统计是对数据进行分类汇总和分析的重要手段,通过合理运用分组统计,可以快速从海量数据中提取有价值的信息,为决策提供有力支持。
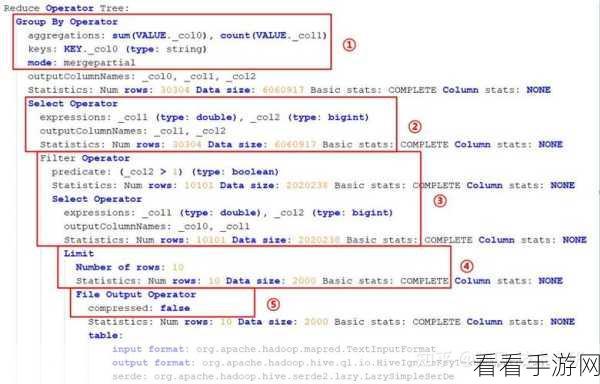
要实现 Hive SQL 的分组统计,需要熟练掌握 GROUP BY 子句和聚合函数的使用,GROUP BY 子句用于指定分组的依据,而聚合函数则用于对每个分组进行计算和汇总,常见的聚合函数包括 SUM(求和)、AVG(平均值)、COUNT(计数)等。
若要统计每个部门的员工人数,可以使用以下语句:
SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department;
在实际应用中,还需要注意一些细节,分组的字段应具有明确的业务逻辑和意义,以确保统计结果的准确性和可用性,对于复杂的分组统计需求,可能需要结合多个表进行关联操作,这就需要对表结构和关联条件有清晰的理解。
为了提高查询性能,在进行分组统计时,应合理创建索引和优化查询语句,避免不必要的全表扫描,减少数据的读取量,从而提高查询效率。
熟练掌握 Hive SQL 的分组统计功能对于处理大规模数据至关重要,通过不断的实践和学习,您将能够更加灵活地运用这一功能,从数据中挖掘出更多有价值的信息,为业务发展提供有力的支持。
参考来源:相关技术文档及实践经验总结。
