探秘 Spark 算法,复杂数据处理的神奇魔法
在当今数字化的时代,数据的复杂性日益凸显,如何有效地处理这些复杂数据成为了众多领域关注的焦点,Spark 算法作为一种强大的工具,在应对复杂数据处理方面展现出了卓越的能力。
Spark 算法具备独特的优势,能够高效地处理大规模的复杂数据,它采用了分布式计算的架构,将数据分布在多个节点上进行并行处理,大大提高了数据处理的速度和效率,Spark 算法还提供了丰富的 API 和数据结构,方便开发者进行灵活的编程和数据操作。
在实际应用中,Spark 算法的处理流程大致可以分为数据读取、数据预处理、数据分析和结果输出等几个主要阶段,在数据读取阶段,Spark 算法能够支持多种数据源的读取,包括文件系统、数据库等,数据预处理阶段则负责对原始数据进行清洗、转换和整合,为后续的分析做好准备,在数据分析阶段,通过运用各种机器学习算法和数据挖掘技术,从海量数据中提取有价值的信息,将分析结果以清晰直观的方式输出,供用户进行决策和应用。
为了更好地发挥 Spark 算法的性能,还需要注意一些关键的技术要点,合理配置资源,包括内存、CPU 等,以确保算法的运行效率,选择合适的数据分区策略和优化数据存储方式也能够显著提升算法的处理效果。
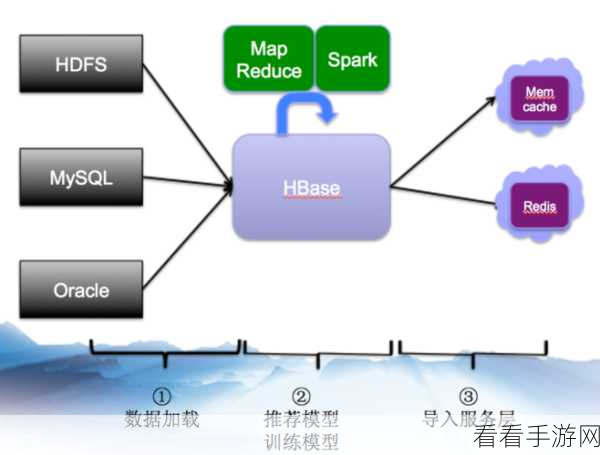
Spark 算法为处理复杂数据提供了一种强大而高效的解决方案,只要深入了解其原理和应用技巧,就能在数据处理的领域中取得出色的成果。
参考来源:相关技术文献及行业研究报告。
