深度解析,Kafka 依赖的优化秘籍
Kafka 作为一款强大的消息队列系统,在众多应用场景中发挥着关键作用,如何优化 Kafka 依赖,使其性能更卓越,是许多开发者面临的挑战。
想要优化 Kafka 依赖,深入理解其工作原理是必不可少的,Kafka 基于分布式架构,通过分区和副本机制来保证数据的可靠性和高可用性,了解这些基本原理,能为后续的优化工作提供坚实的理论基础。

优化 Kafka 依赖的关键之一在于合理配置参数,调整缓冲区大小、消息批次大小和发送频率等参数,可以显著提升性能,不同的业务场景需要不同的参数配置,需要根据实际情况进行细致的测试和调整。
对于 Kafka 依赖的优化,还需关注消费者和生产者的处理逻辑,优化消费者的拉取策略,确保及时有效地获取数据;优化生产者的发送逻辑,避免消息堆积和延迟。
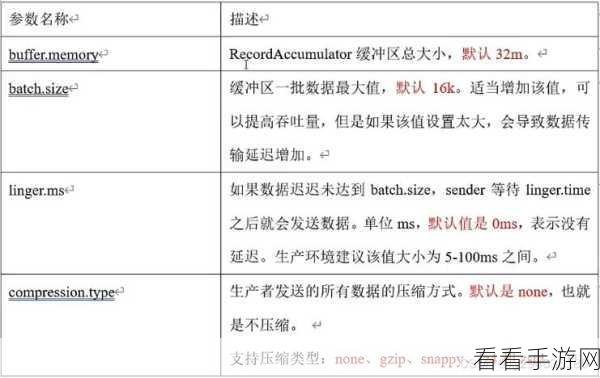
监控和性能测试也是优化过程中不可或缺的环节,通过实时监控关键指标,如吞吐量、延迟、内存使用等,能够及时发现问题并采取相应措施,定期进行性能测试,对比不同优化方案的效果,找到最适合的优化策略。
优化 Kafka 依赖是一个综合性的工作,需要从多个方面入手,结合实际业务需求,不断探索和实践,才能实现最佳的性能提升。
参考来源:相关技术文档和实践经验总结。
