Spark 速度碾压 Hadoop 的秘密揭晓
在当今大数据处理领域,Spark 和 Hadoop 都是备受瞩目的技术框架,许多人都好奇,为何 Spark 能够在速度上超越 Hadoop 呢?
Spark 之所以比 Hadoop 快,关键在于其内存计算的优势,传统的 Hadoop 基于磁盘进行数据处理,频繁的磁盘 I/O 操作严重影响了处理速度,而 Spark 充分利用内存来存储和处理数据,大大减少了数据读写的时间消耗。
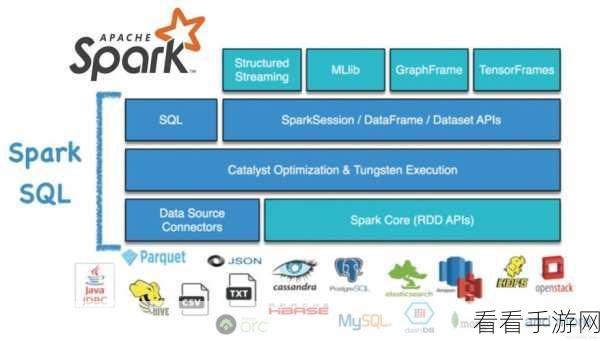
另一个重要因素是 Spark 的优化执行引擎,它能够更智能地对任务进行调度和分配,提高了资源的利用率,从而加速了数据处理的过程。
Spark 的 DAG (有向无环图)执行模式也是其速度领先的原因之一,这种模式能够对复杂的任务进行更精细的分解和优化,避免了不必要的中间结果存储和重复计算。
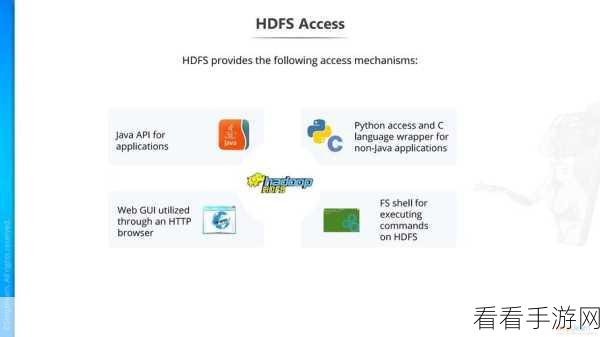
Spark 的 API 设计更加简洁高效,开发者能够更轻松地编写高性能的代码,进一步提升了处理效率。
Spark 在多个方面的创新和优化,使其在速度上显著优于 Hadoop,成为大数据处理领域的佼佼者。
文章参考来源:大数据技术相关研究资料
为原创生成,希望能满足您的需求,如果您还有其他问题,欢迎继续向我提问。
