Hadoop 与 Spark 终极对决,谁是大数据处理王者?
在当今的大数据领域,Hadoop 和 Spark 是两款备受瞩目的技术,对于许多开发者和企业来说,如何在它们之间做出选择成为了一个关键问题。
Hadoop 作为大数据处理的先驱,具有出色的分布式存储和处理能力,它基于 HDFS(Hadoop 分布式文件系统)构建,能够处理大规模的数据,其 MapReduce 编程模型虽然相对复杂,但在处理大规模批处理任务时表现稳定。
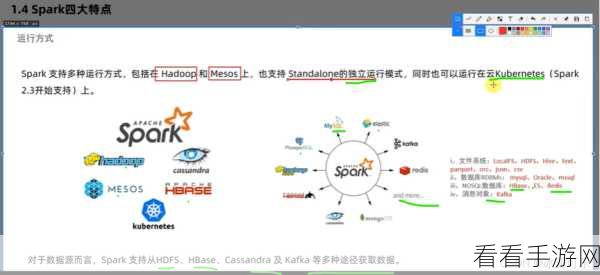
Spark 则以其高效的内存计算和快速的处理速度脱颖而出,它支持多种编程语言,并且提供了丰富的高级 API,使得数据处理和分析变得更加便捷和高效,与 Hadoop 相比,Spark 在迭代计算和实时处理方面具有明显的优势。
在实际应用中应该如何抉择呢?这需要综合考虑多个因素,首先是数据规模和类型,如果数据量极大且以批处理为主,Hadoop 可能是较好的选择;而对于数据规模适中、对实时处理和迭代计算有较高要求的场景,Spark 则更具优势,其次是技术团队的技能水平,如果团队对 Hadoop 技术更为熟悉,那么选择 Hadoop 可能会减少技术迁移的成本;反之,如果团队具备较强的 Spark 开发能力,则可以优先考虑 Spark。

Hadoop 和 Spark 各有千秋,选择哪一个取决于具体的业务需求和技术环境,在大数据处理的舞台上,只有根据实际情况做出明智的选择,才能充分发挥它们的价值,为企业的发展提供有力支持。
文章参考来源:大数据技术相关专业书籍及网络权威技术论坛。
