深入探究,Hadoop 与 Spark 的显著差异
Hadoop 和 Spark 是大数据领域中两个重要的技术框架,但它们在诸多方面存在着明显的区别。
Hadoop 是一个分布式系统基础架构,主要用于大规模数据存储和处理,它采用了分布式文件系统 HDFS 来存储数据,通过 MapReduce 计算模型进行数据处理,Hadoop 的优势在于其出色的可扩展性和对大规模数据的处理能力,能够处理 PB 级别的数据,Hadoop 的 MapReduce 计算模型在处理某些复杂的计算任务时,可能会显得效率较低。
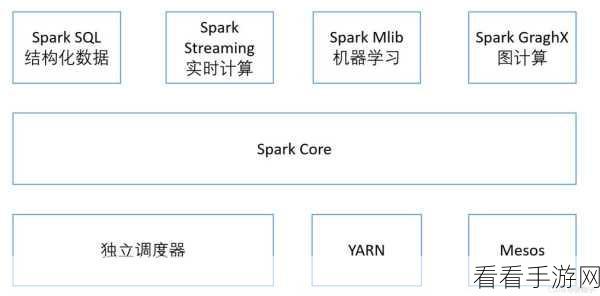
Spark 则是一种快速、通用的大数据计算引擎,它在内存中进行计算,大大提高了数据处理的速度,Spark 支持多种高级编程语言,如 Java、Scala、Python 等,为开发者提供了更多的选择,与 Hadoop 相比,Spark 不仅在处理速度上具有优势,还提供了更丰富的 API 和更高的编程灵活性。
在数据存储方面,Hadoop 依赖 HDFS,而 Spark 可以与多种数据源进行集成,包括 HDFS、本地文件系统、关系型数据库等,这使得 Spark 在数据接入和处理上更加灵活多样。
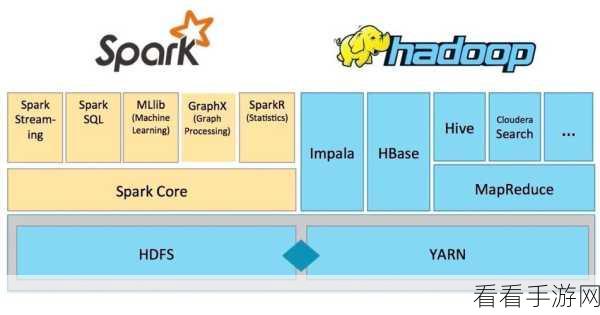
在处理数据的类型上,Hadoop 更适合处理批处理数据,而 Spark 不仅支持批处理,还能很好地处理流数据和交互式查询。
Hadoop 和 Spark 各有其特点和优势,在实际应用中,应根据具体的业务需求和数据特点来选择合适的技术框架。
文章参考来源:大数据技术相关书籍及网络权威技术文章。
