深度解析,Spark 算法引领分布式计算的奥秘
Spark 算法,作为分布式计算领域的关键技术,正发挥着日益重要的作用,它的出现,为处理海量数据提供了高效且可靠的解决方案。
Spark 算法之所以能够实现分布式计算,关键在于其独特的架构设计和优化策略,它采用了弹性分布式数据集(RDD)的概念,这是一种容错的、可并行操作的数据结构,通过将数据分割成多个分区,并在不同的节点上并行处理,大大提高了计算效率,Spark 算法拥有先进的任务调度机制,能够根据数据的分布和计算资源的可用性,智能地分配任务,确保计算任务的高效执行,它还支持多种数据存储格式和数据源,能够与不同的系统进行无缝集成,为数据处理提供了极大的灵活性。

在实际应用中,Spark 算法在大数据分析、机器学习、实时数据处理等领域都展现出了卓越的性能,在大数据分析中,它能够快速地对海量数据进行筛选、聚合和统计分析,为企业提供有价值的决策支持,在机器学习领域,它可以高效地处理训练数据,加速模型的训练过程,而在实时数据处理方面,Spark Streaming 组件能够实现秒级甚至毫秒级的延迟,满足实时性要求较高的业务场景。
要成功运用 Spark 算法实现分布式计算,还需要注意一些关键要点,一是合理配置计算资源,包括内存、CPU 等,以充分发挥算法的性能,二是优化数据存储和读取方式,选择合适的数据格式和存储引擎,提高数据访问效率,三是精心设计算法和任务流程,避免不必要的重复计算和数据传输。
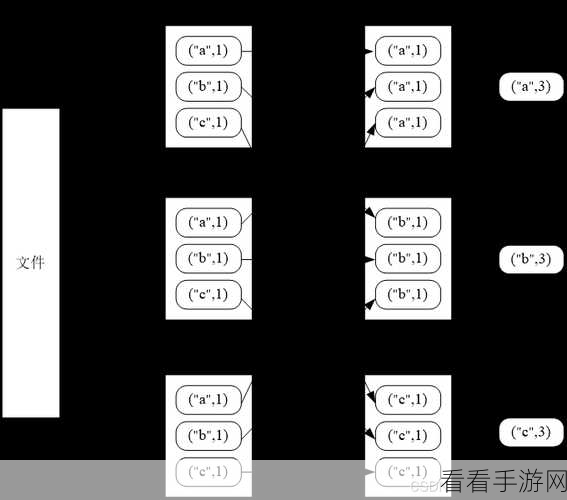
Spark 算法为分布式计算开辟了新的道路,但其应用并非一蹴而就,需要我们深入理解其原理和机制,并结合实际业务需求进行优化和调整,才能充分发挥其优势,为数据处理和分析带来更大的价值。
参考来源:相关技术文档和行业研究报告。
