破解 Spark 算法数据倾斜难题的终极秘籍
在当今的大数据处理领域,Spark 算法的应用愈发广泛,数据倾斜问题却常常成为其性能提升的拦路虎,如何有效地避免数据倾斜,实现更高效的数据处理呢?
Spark 算法中的数据倾斜,指的是数据分布不均匀,导致某些任务处理的数据量远远大于其他任务,从而拖慢整个作业的执行速度,造成数据倾斜的原因多种多样,比如数据本身的特性、业务逻辑的复杂性以及算法的不合理使用等。
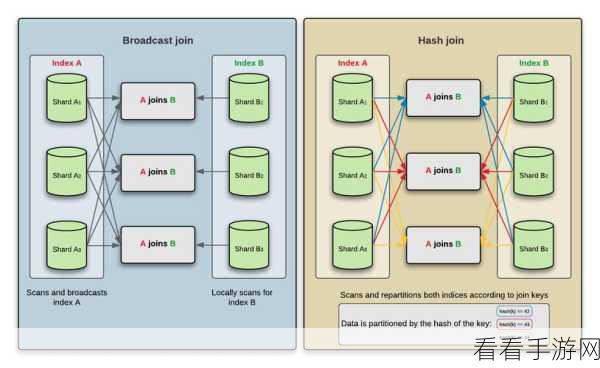
要避免数据倾斜,关键在于对数据的预处理,在数据输入阶段,就需要对数据进行仔细的分析和清洗,通过去除重复数据、纠正错误数据以及对数据进行合理的分区,可以有效地减少数据倾斜的可能性,如果数据中存在某些热点键值,在分区时可以将其单独处理,避免它们集中在少数分区中。
选择合适的算法和操作也能在一定程度上减轻数据倾斜的影响,在进行聚合操作时,可以使用更具鲁棒性的算法,如基于抽样的聚合算法,这种算法通过对数据进行抽样来估计聚合结果,从而避免了对大规模数据的直接处理,降低了数据倾斜的风险。
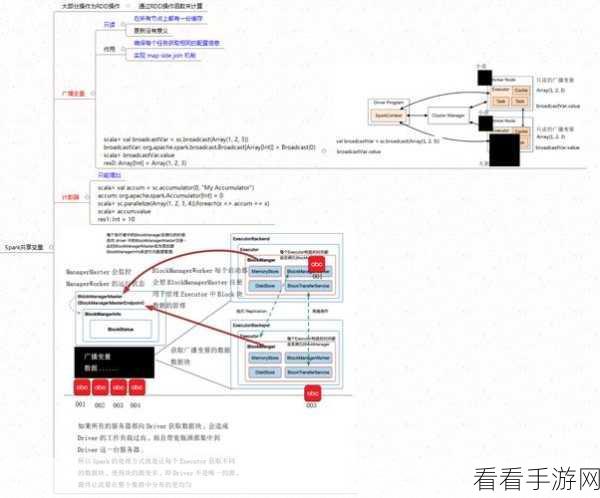
调整 Spark 配置参数也是解决数据倾斜问题的重要手段,通过合理设置 executor 内存、并行度等参数,可以优化任务的分配和执行,提高系统的整体性能,增加并行度可以将数据更均匀地分配到多个任务中,从而减轻单个任务的数据处理压力。
在实际应用中,还需要结合具体的业务场景和数据特点,灵活运用上述方法,不断地进行性能测试和优化,及时发现并解决可能出现的数据倾斜问题,只有这样,才能充分发挥 Spark 算法的优势,实现高效的数据处理和分析。
参考来源:大数据处理相关技术文档及实践经验总结。
仅供参考,您可以根据实际需求进行调整和修改。
