Python Spider 爬虫必备,错误处理的精妙策略
在当今数字化的时代,Python Spider 爬虫技术的应用愈发广泛,在爬虫过程中,错误处理是一个至关重要的环节,如果不能妥善处理错误,可能会导致爬虫任务的失败,甚至引发一系列的问题。
Python Spider 爬虫的错误处理策略究竟有哪些呢?

首先要提到的是异常捕获,当爬虫在运行过程中遇到异常情况,如网络连接中断、页面无法访问等,通过异常捕获机制可以及时发现并采取相应的措施,在代码中使用 try-except 语句来捕获可能出现的异常,并在 except 块中进行错误处理。
设置重试机制,错误可能是暂时的,例如网络波动导致的连接失败,通过设置合理的重试次数和间隔时间,可以增加爬虫获取数据的成功率,但需要注意的是,重试次数不能过多,以免造成不必要的资源浪费和时间消耗。
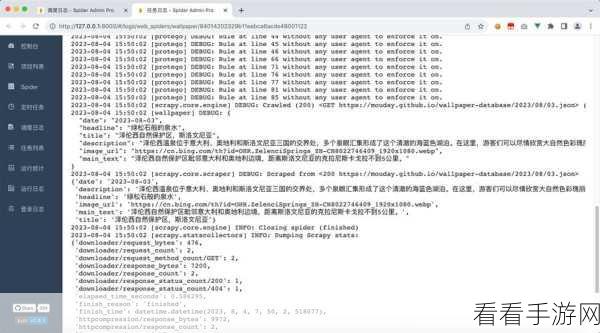
日志记录也是错误处理中不可或缺的一部分,详细的日志可以帮助我们了解爬虫运行过程中出现的问题,便于后续的分析和优化,在日志中记录错误的类型、发生的时间、相关的上下文信息等,有助于快速定位和解决问题。
要对错误进行分类和处理,不同类型的错误可能需要不同的处理方式,对于无法获取数据的错误,可以选择跳过当前页面,继续爬取下一个页面;对于严重的错误,如程序崩溃,则需要及时停止爬虫并进行修复。
掌握有效的 Python Spider 爬虫错误处理策略,能够让我们的爬虫更加稳定、高效地运行,从而获取到有价值的数据。
文章参考来源:相关技术文档及个人实践经验总结。
