深入探究,Spark GroupBy 操作的简便性与技巧
Spark 的 GroupBy 操作是数据处理中的关键环节,但其简便性一直备受开发者关注。
在大数据处理领域,Spark 凭借其强大的功能和高效的性能,成为众多开发者的首选工具,而 GroupBy 操作作为其中的重要操作之一,对于数据的分组和聚合起着至关重要的作用。
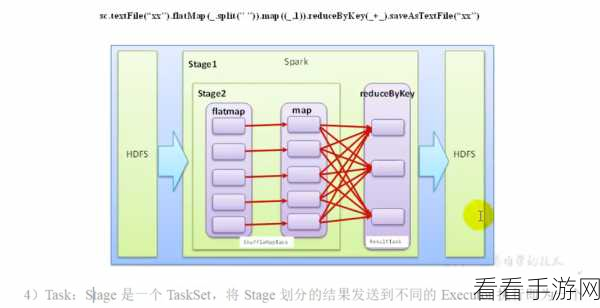
Spark 的 GroupBy 操作到底简便与否呢?这需要从多个方面来进行分析。
从语法结构上来看,Spark 的 GroupBy 操作相对简洁明了,通过使用特定的函数和参数,开发者可以轻松地指定分组的依据和聚合的方式,使用“groupBy(“column_name”)”这样的语句就能快速按照指定的列进行分组。

在性能方面,Spark 的 GroupBy 操作经过了优化,能够在处理大规模数据时保持较高的效率,它采用了分布式计算的方式,将数据分布在多个节点上进行并行处理,大大缩短了处理时间。
要实现高效的 GroupBy 操作,也需要注意一些要点,数据的分布和分区策略对性能有着重要影响,合理地设置分区数量和分区方式,可以避免数据倾斜,提高处理效率。
对于复杂的业务逻辑,可能需要结合其他操作,如 join、filter 等,来实现更精确的数据处理。
Spark 的 GroupBy 操作在一定程度上是简便且高效的,但需要开发者深入理解其原理和特点,并根据实际业务需求进行合理的运用和优化,才能充分发挥其优势。
参考来源:大数据处理相关技术文档和实践经验。
仅供参考,希望能对您有所帮助。
