探索 Hadoop 与 Spark 强大的数据处理能力
在当今数字化时代,数据处理成为了企业和组织发展的关键,而 Hadoop 和 Spark 作为两款重要的数据处理工具,它们的能力备受关注。
Hadoop 以其分布式存储和并行计算的特点,为大规模数据处理提供了坚实的基础,它能够处理海量的数据,并通过分布式的方式将计算任务分配到多个节点上,从而实现高效的数据处理。
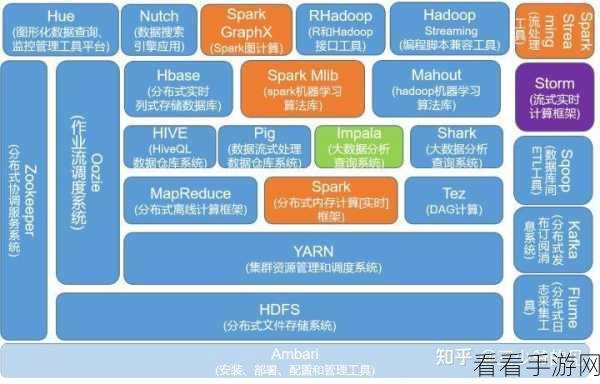
Spark 则在性能和灵活性方面表现出色,它基于内存计算,大大提高了数据处理的速度,Spark 提供了丰富的 API 和高级的编程模型,使得数据处理的开发更加便捷和高效。
要充分发挥 Hadoop 和 Spark 的数据处理能力,需要合理的架构设计和优化配置,在数据存储方面,要根据数据的特点和访问模式选择合适的存储格式和分区策略,在计算任务的分配上,要考虑节点的性能和负载均衡,以确保任务能够快速完成。
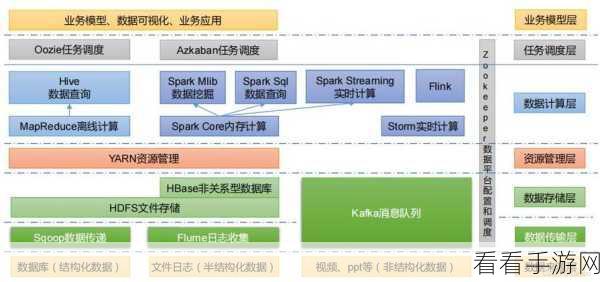
数据的预处理和清洗也是至关重要的环节,在将数据输入到 Hadoop 或 Spark 进行处理之前,需要对数据进行筛选、转换和去重等操作,以提高数据的质量和处理效率。
在实际应用中,Hadoop 和 Spark 常常结合使用,以满足不同场景的需求,对于大规模的历史数据存储和批处理任务,Hadoop 是不二之选;而对于实时性要求较高的数据分析和处理,Spark 则能发挥更大的优势。
Hadoop 和 Spark 凭借其独特的优势,在数据处理领域占据着重要的地位,通过深入了解它们的特点和合理运用,能够为企业和组织带来更高效、更精准的数据处理能力,从而在竞争激烈的市场中赢得先机。
文章参考来源:相关技术文档及行业研究报告。
