破解 Hive Shuffle 处理海量大数据的秘诀
在当今数字化时代,数据量的爆炸式增长给处理和分析带来了巨大挑战,Hive Shuffle 在应对大数据量时的处理方式备受关注。
Hive Shuffle 是 Hive 框架中的一个关键环节,它对大数据量的处理效果直接影响着整个数据分析流程的效率和准确性,如何有效地处理大数据量呢?

要理解 Hive Shuffle 处理大数据量的方法,首先需要明确其工作原理,Hive Shuffle 主要负责将具有相同键值的数据分发到同一个 reducer 中进行处理,这个过程中涉及到数据的重新分区和排序。
优化 Hive Shuffle 处理大数据量的一个重要方面是调整相关配置参数,合理设置 reducer 的数量可以有效地平衡计算资源的分配,避免出现某些 reducer 负载过高而其他 reducer 闲置的情况。
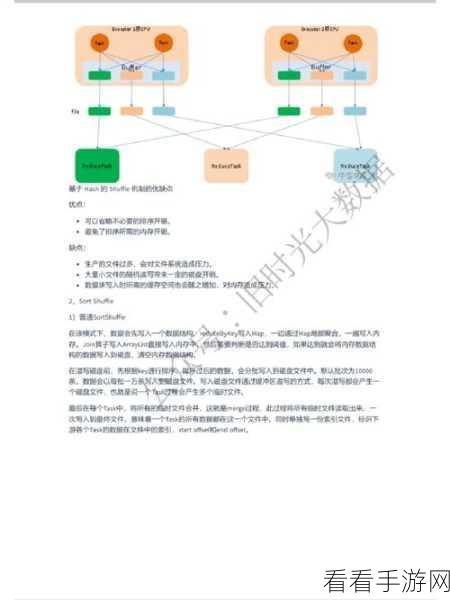
数据的预处理也是提升 Hive Shuffle 处理大数据量性能的关键,在数据进入 Shuffle 阶段之前,对数据进行清洗、筛选和压缩等操作,可以减少数据量,提高处理效率。
选择合适的存储格式对于 Hive Shuffle 处理大数据量也至关重要,不同的存储格式在数据读取和处理速度上存在差异,根据数据特点选择合适的存储格式能够显著改善性能。
要想让 Hive Shuffle 在处理大数据量时表现出色,需要综合考虑工作原理、配置参数、数据预处理和存储格式等多个方面,通过不断的实践和优化找到最适合的解决方案。
参考来源:相关技术文档及行业研究报告。
仅供参考,您可以根据实际需求进行调整和修改。
