探秘 Spark GroupBy 的准确性保障秘籍
Spark GroupBy 操作在大数据处理中扮演着至关重要的角色,其准确性直接影响到数据分析的结果和决策的可靠性,如何确保 Spark GroupBy 的准确性呢?
要保证 Spark GroupBy 的准确性,数据的预处理至关重要,在进行 GroupBy 操作之前,需要对数据进行清洗、筛选和转换,去除无效数据和异常值,确保数据的质量和一致性,只有高质量的数据输入,才能为准确的 GroupBy 结果奠定基础。

合理配置 Spark 的相关参数也是关键之一,调整内存分配、并行度和缓存策略等参数,可以优化 GroupBy 操作的性能和准确性,不同的数据集和应用场景需要不同的参数配置,需要通过实验和测试来找到最适合的参数组合。
选择合适的算法和数据结构同样不容忽视,Spark 提供了多种 GroupBy 的实现方式,如 HashBasedGroupBy 和 SortBasedGroupBy,根据数据的特点和规模,选择合适的算法可以提高 GroupBy 的效率和准确性。
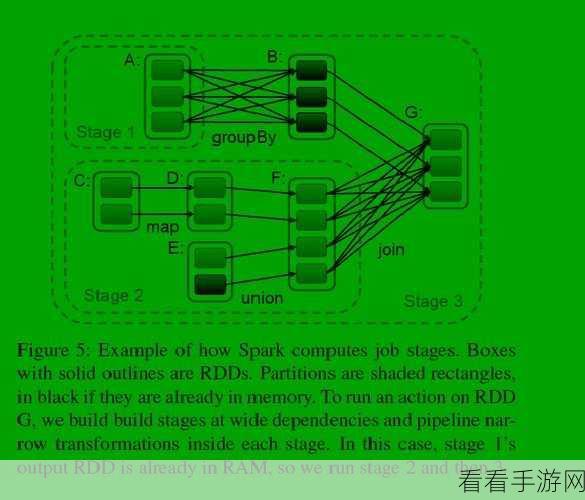
对 GroupBy 结果进行验证和监控也是必不可少的环节,可以通过与已知的正确结果进行对比、使用数据质量工具进行检查,以及设置监控指标来及时发现可能存在的准确性问题,并采取相应的措施进行修复和优化。
要保证 Spark GroupBy 的准确性,需要从数据预处理、参数配置、算法选择和结果验证等多个方面入手,综合考虑和优化,才能在大数据处理中获得准确可靠的 GroupBy 结果。
参考来源:相关技术文档及实践经验总结。
仅供参考,您可以根据实际需求进行调整和修改。
