深入探究,Hadoop 与 Spark 数据传输效率究竟如何?
Hadoop 和 Spark 作为大数据处理领域的重要技术,它们之间的数据传输效率一直备受关注。
Hadoop 是一个分布式系统基础架构,具有可靠、高效、可伸缩的特点,而 Spark 则以其快速的处理速度和强大的内存计算能力在大数据处理中崭露头角。
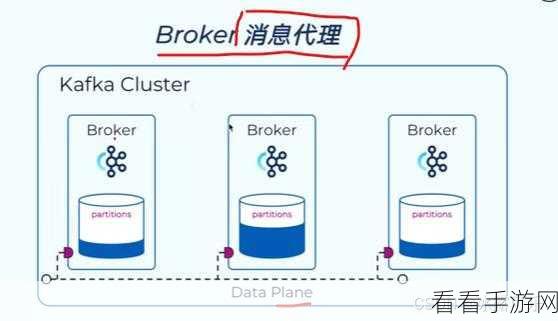
要探讨 Hadoop 与 Spark 数据传输效率,首先得了解它们的数据存储和处理方式,Hadoop 通常使用 HDFS 来存储数据,其数据读取和写入是通过批量处理来实现的,而 Spark 支持多种数据源,包括 HDFS、本地文件系统等,并且在数据处理上更加灵活。
在数据传输过程中,网络带宽是一个重要的影响因素,如果网络带宽不足,那么数据传输的速度就会受到限制,数据的规模和数据类型也会对传输效率产生影响。
为了提高 Hadoop 与 Spark 之间的数据传输效率,可以采取一些优化措施,合理配置网络参数,确保网络的稳定性和带宽的充足性,对数据进行压缩可以减少数据量,从而提高传输速度。
选择合适的数据格式也能提升传输效率,一些高效的数据格式如 Parquet、ORC 等,可以在存储和传输过程中节省空间和提高效率。
Hadoop 与 Spark 数据传输效率的高低取决于多种因素,需要综合考虑并采取相应的优化策略,才能在大数据处理中实现高效的数据传输。
文章参考来源:大数据技术相关研究文献及行业实践经验。
