深入解析,Hadoop 与 Spark 容错机制的奥秘
在当今的大数据处理领域,Hadoop 和 Spark 是两个备受瞩目的技术框架,它们在处理海量数据时,容错机制的重要性不言而喻,Hadoop 与 Spark 的容错机制究竟是怎样的呢?
Hadoop 的容错机制主要依赖于其分布式文件系统 HDFS 的副本机制,HDFS 会将数据存储在多个节点上,并生成多个副本,当某个节点出现故障时,其他副本可以保证数据的可用性,这种副本机制确保了数据的可靠性,即使在节点故障的情况下,也不会导致数据的丢失。
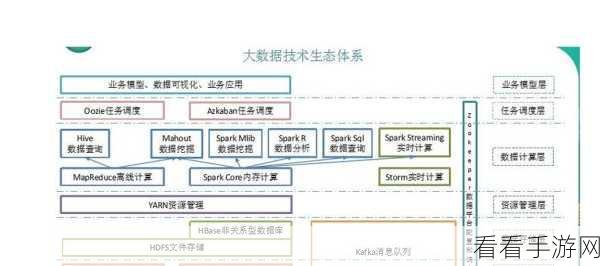
Spark 则采用了不同的容错策略,它通过弹性分布式数据集(RDD)的血统(Lineage)来实现容错,当某个 RDD 的分区丢失时,Spark 可以根据血统信息重新计算该分区,从而恢复数据,Spark 还支持检查点(Checkpoint)机制,将重要的 RDD 数据持久化到可靠的存储中,以提高容错性能。
在实际应用中,了解 Hadoop 和 Spark 的容错机制对于优化系统性能、提高数据处理的可靠性具有重要意义,合理设置副本数量、选择合适的检查点策略等,都可以在保证容错性的同时,提高系统的效率。
深入研究 Hadoop 与 Spark 的容错机制,能够帮助我们更好地运用这两个强大的技术框架,应对各种复杂的数据处理场景。
文章参考来源:相关技术文档及大数据处理领域的专业研究。
