探秘 Spark 函数处理图数据的奇妙机制
Spark 函数在处理图数据领域发挥着至关重要的作用,它以独特的方式和高效的性能,为数据分析带来了全新的可能。
Spark 函数处理图数据的优势众多,其具备强大的并行计算能力,能够快速处理大规模的图数据,这意味着在面对海量的节点和边时,Spark 函数能够迅速地进行计算和分析,大大缩短了处理时间,它提供了丰富的操作接口和算法库,满足了不同类型和复杂度的图数据处理需求,无论是图的遍历、最短路径计算,还是社区发现等复杂任务,都能找到相应的函数和方法来实现。
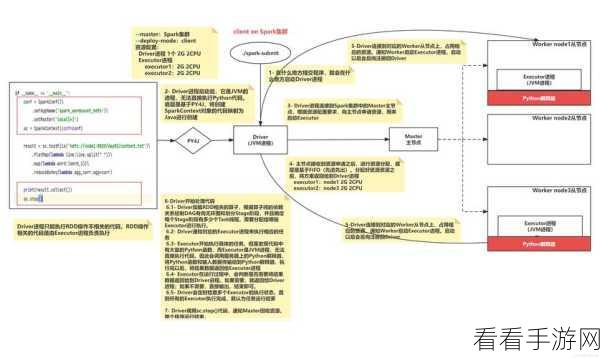
要深入理解 Spark 函数处理图数据的工作原理,需要从几个关键方面入手,数据的分区策略是其中的重要一环,通过合理地将图数据划分到不同的分区,Spark 函数能够实现并行处理,充分利用集群的计算资源,缓存机制也起到了关键作用,对经常使用的数据进行缓存,可以避免重复计算,提高处理效率。
在实际应用中,还需要注意一些问题,数据的分布不均匀可能导致某些分区的计算负担过重,影响整体性能,参数的调整也需要根据具体的图数据特点和处理任务进行优化,以达到最佳的效果。
掌握 Spark 函数处理图数据的工作方式,对于提升数据分析的能力和效率具有重要意义,不断探索和实践,才能更好地发挥其在图数据处理领域的强大作用。
文章参考来源:相关技术文档和学术研究论文。
