Spark GroupBy 数据规模的奥秘与实战指南
Spark GroupBy 操作在处理大规模数据时发挥着重要作用,但对于其适用的数据规模,很多开发者仍存在疑惑。
要理解 Spark GroupBy 适用的数据规模,我们需要先明确几个关键因素,首先是数据的特征,包括数据的分布、重复度以及数据字段的类型和数量等,不同特征的数据在进行 GroupBy 操作时,对资源的需求和处理效率会有很大差异,其次是集群的配置,包括内存、CPU 核心数和网络带宽等,强大的集群配置能够支持处理更大规模的数据,算法的优化也是影响因素之一,合理选择 GroupBy 的实现方式和参数设置,可以显著提升处理性能。

在实际应用中,我们可以通过一些方法来评估 Spark GroupBy 适用的数据规模,进行小规模的测试,逐步增加数据量,观察处理时间和资源消耗的变化趋势,还可以参考类似业务场景下的经验数据,以及借鉴行业内的最佳实践案例。
为了更好地应对不同规模的数据,我们可以采取一些优化策略,对于较小规模的数据,可以利用内存缓存来提高处理速度;对于大规模数据,则需要合理分区和调整并行度,以充分利用集群资源,要注意数据的预处理,去除不必要的字段和重复数据,减少计算量。
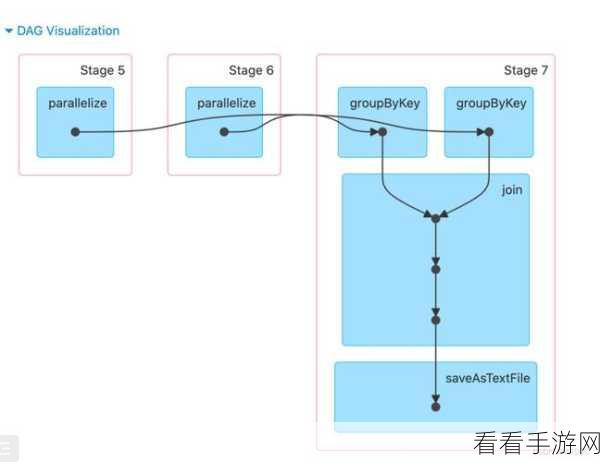
了解 Spark GroupBy 适用的数据规模并非一蹴而就,需要综合考虑多种因素,并结合实际业务需求和集群环境进行不断的测试和优化。
参考来源:相关技术文档及行业经验分享
为原创生成,希望能满足您的需求。
