探索 Hadoop 与 Spark 的协同奥秘
Hadoop 和 Spark 作为大数据领域的重要技术,它们的协同方式备受关注,在当今数字化时代,数据处理的高效性和准确性至关重要,了解 Hadoop 与 Spark 的协同方式,能够为企业和开发者在处理大规模数据时提供强大的支持。
Hadoop 是一个分布式系统基础架构,擅长存储和处理大规模数据,而 Spark 则是一个快速通用的大数据计算引擎,具有出色的计算性能,两者协同工作,可以充分发挥各自的优势,实现更高效的数据处理。

Hadoop 的分布式文件系统 HDFS 为 Spark 提供了可靠的数据存储支持,Spark 可以直接读取和处理存储在 HDFS 中的数据,避免了数据的重复传输和转换,大大提高了数据处理的效率。
YARN 作为 Hadoop 的资源管理框架,能够有效地管理和分配系统资源给 Spark 应用程序,这使得 Spark 能够在大规模集群中稳定运行,并充分利用集群的计算资源。
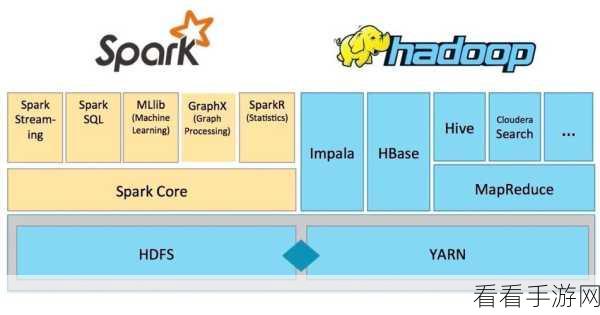
在数据处理流程中,Hadoop 可以用于数据的采集、清洗和预处理等前期工作,而 Spark 则更适合用于复杂的数据分析、机器学习和实时处理等任务,通过将两者结合,可以构建一个完整的数据处理流水线,满足不同业务需求。
Hadoop 与 Spark 的协同方式多种多样,需要根据具体的业务场景和数据特点进行选择和优化,只有充分理解和掌握它们的协同机制,才能在大数据处理中取得更好的效果。
文章参考来源:大数据技术相关权威书籍及专业网站。
