深入探究,Hadoop 与 Spark 性能的巅峰对决
Hadoop 和 Spark 作为大数据领域的重要技术,它们的性能对比一直备受关注。
Hadoop 是一个分布式系统基础架构,具有出色的存储和处理大规模数据的能力,它通过分布式文件系统 HDFS 实现数据的可靠存储,并利用 MapReduce 计算框架进行数据处理,Hadoop 在处理迭代计算和实时数据方面存在一定的局限性。
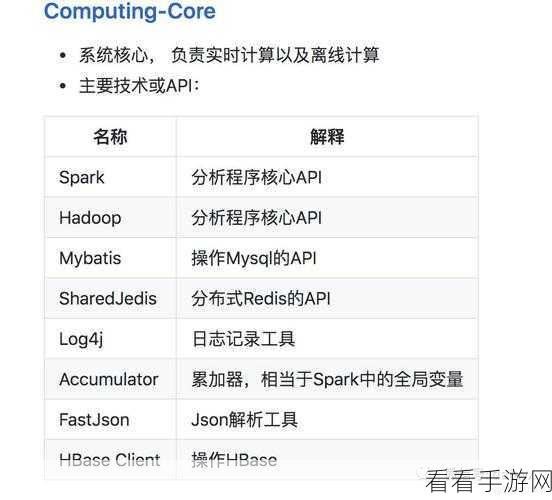
Spark 则是一种快速通用的大数据计算引擎,它基于内存计算,能够大大提高数据处理的速度,尤其是在迭代计算和实时数据处理方面表现出色,Spark 还提供了丰富的 API,支持多种编程语言,使得开发和应用更加便捷。
在性能方面,Hadoop 适用于大规模数据的批处理,对于数据量巨大且处理逻辑相对简单的任务,能够稳定高效地完成,但由于其磁盘 I/O 操作较多,处理速度相对较慢。
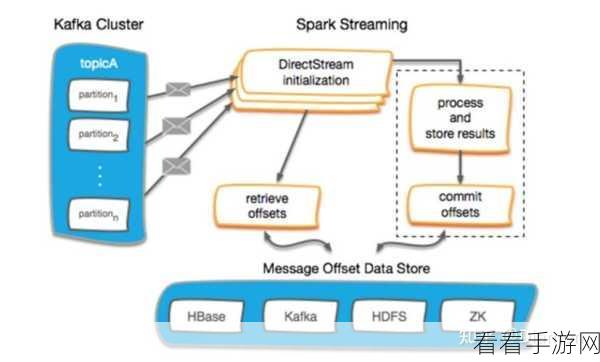
而 Spark 凭借内存计算的优势,在处理速度上明显快于 Hadoop,对于需要快速响应和实时处理的场景,如实时数据分析、流处理等,Spark 是更好的选择。
需要注意的是,性能的优劣并非绝对,还需要根据具体的应用场景和需求来综合考虑,在数据量较小、计算逻辑简单的情况下,Hadoop 可能仍然是一个可行的选择,而对于对处理速度要求极高、数据实时性强的应用,Spark 则更能发挥其优势。
Hadoop 和 Spark 各有优劣,在实际应用中,应根据具体情况合理选择,以实现最佳的性能和效果。
文章参考来源:大数据技术相关研究资料。
