探索 Hadoop 与 Spark 的未来之路,机遇与挑战并存
在当今的大数据领域,Hadoop 和 Spark 无疑是两颗璀璨的明星,它们的未来发展方向却充满了未知和变数。
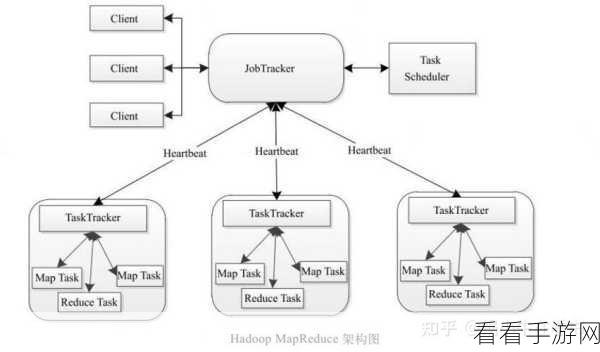
Hadoop 作为大数据处理的先驱框架,其在数据存储和批处理方面有着深厚的根基,但随着技术的不断演进,它也面临着诸多挑战,在处理实时数据和复杂的机器学习任务时,Hadoop 的表现可能不尽如人意。
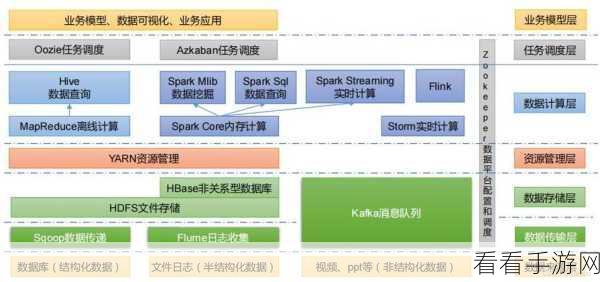
Spark 则以其高效的内存计算和快速的数据处理能力迅速崛起,它能够更好地应对实时数据处理和迭代计算的需求,在数据挖掘和机器学习等领域展现出了巨大的潜力。
尽管 Hadoop 和 Spark 都有着各自的优势和局限性,但未来的发展趋势并非是二者的简单竞争,而是相互融合与互补,Hadoop 可以通过与 Spark 的集成,提升其在实时数据处理方面的能力;Spark 也能借助 Hadoop 的大规模数据存储优势,更好地发挥其计算效能。
云计算的兴起也为 Hadoop 和 Spark 的发展带来了新的机遇,云服务提供商不断优化其大数据处理服务,使得用户能够更加便捷地使用 Hadoop 和 Spark 来处理海量数据。
在技术创新的驱动下,Hadoop 和 Spark 未来有望在数据治理、人工智能融合等方面取得更大的突破,要实现这些目标,还需要开发者和企业不断探索和创新,以适应快速变化的市场需求和技术环境。
文章参考来源:行业专家分析及相关技术论坛讨论。
仅供参考,您可以根据实际需求进行调整。
