深度解析,Hadoop 与 Spark 整合的关键难点
Hadoop 和 Spark 作为大数据领域的重要技术,它们的整合一直是众多开发者关注的焦点,这一整合过程并非一帆风顺,存在着诸多难点。
Hadoop 与 Spark 整合的难点主要体现在技术架构的差异上,Hadoop 基于分布式文件系统 HDFS 和 MapReduce 计算模型,而 Spark 则采用了更加先进的内存计算和弹性分布式数据集(RDD),这种架构上的差异导致在整合过程中需要解决数据存储和处理方式的协调问题。
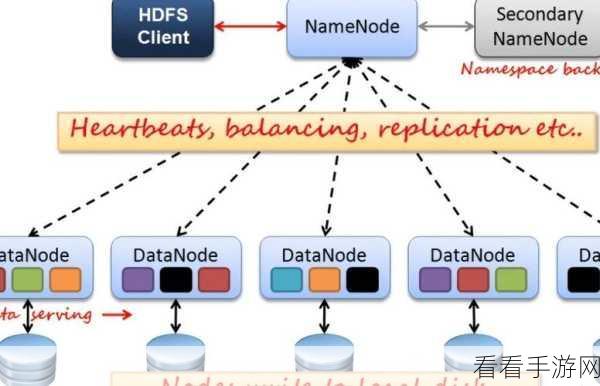
数据格式的兼容性也是一个不容忽视的难点,Hadoop 中的数据格式多样,如文本、序列文件等,而 Spark 对数据格式有着特定的要求,在整合时,需要确保数据在不同框架之间能够顺利转换和共享,避免数据格式的不兼容导致数据丢失或处理错误。
资源管理是整合中的另一个挑战,Hadoop 通常依赖 YARN 进行资源调度和管理,而 Spark 也有自己的资源管理机制,如何在一个系统中实现两者资源的合理分配和高效利用,以避免资源竞争和浪费,是需要重点考虑的问题。
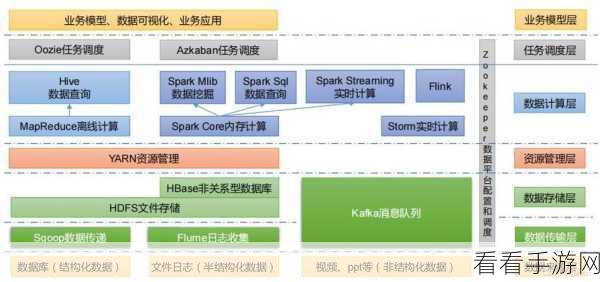
性能优化也是整合过程中的关键,不同的应用场景和数据特点对 Hadoop 和 Spark 的性能要求各异,要实现整合后的系统性能最优,需要深入了解两者的性能特点,进行针对性的配置和调优。
Hadoop 与 Spark 的整合是一个复杂而具有挑战性的任务,需要开发者在技术架构、数据格式、资源管理和性能优化等多个方面下功夫,才能实现两者的优势互补,构建高效稳定的大数据处理平台。
参考来源:大数据技术相关研究文献及行业实践经验
