深入探究,Hadoop 与 Spark 的完美整合之道
Hadoop 和 Spark 作为大数据领域的重要技术,它们的整合一直是众多开发者关注的焦点。
Hadoop 以其强大的分布式存储能力而闻名,Spark 则在数据处理速度和实时性方面表现出色,将二者进行整合,能够充分发挥各自的优势,为大数据处理带来更高效、更灵活的解决方案。
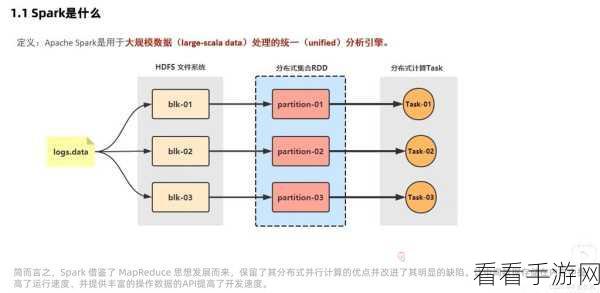
在整合 Hadoop 与 Spark 时,需要注意以下几个关键方面,首先是数据存储与读取的优化,Hadoop 的 HDFS 作为数据存储的基础,要确保 Spark 能够高效地读取和写入数据,这涉及到配置合适的存储格式、优化数据分区等操作,其次是资源管理的协调,Hadoop 的 YARN 负责资源的分配和调度,而 Spark 也有自身的资源管理机制,需要在两者之间找到最佳的平衡,以避免资源竞争和浪费,再者是任务调度的整合,确保 Hadoop 的 MapReduce 任务和 Spark 任务能够在同一个集群中合理地分配和执行,提高整个系统的资源利用率。
要实现 Hadoop 与 Spark 的成功整合,还需要掌握一些实用的技术和工具,使用合适的连接器和 API,如 Spark 提供的 Hadoop 相关的连接器,能够方便地实现数据的交互,对集群的性能进行监控和调优也是至关重要的,通过监控关键指标,如内存使用、CPU 利用率、网络带宽等,及时发现和解决可能出现的性能瓶颈。

Hadoop 与 Spark 的整合并非一蹴而就,需要深入理解两者的工作原理和特点,结合实际的业务需求和数据处理场景,进行精心的配置和优化,只有这样,才能充分发挥它们的优势,为大数据处理带来更出色的表现。
文章参考来源:大数据技术相关书籍及权威技术论坛。
