深入探究,Hadoop 与 Spark 的独特优势大揭秘
Hadoop 和 Spark 是大数据领域中备受瞩目的技术框架,它们各自拥有独特的优势,为数据处理和分析带来了巨大的变革。
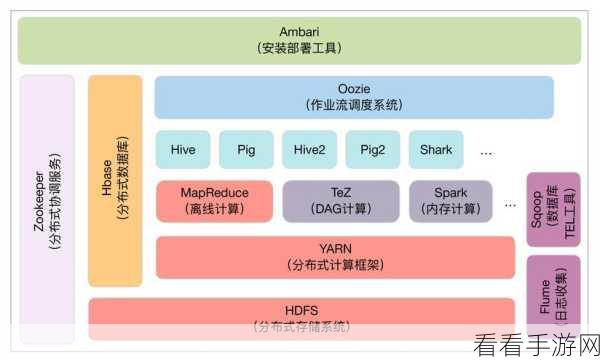
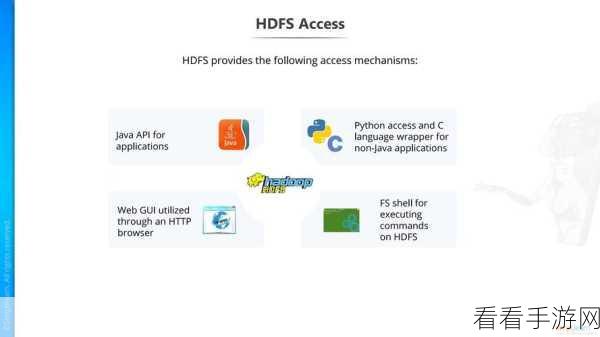
Hadoop 最大的优势在于其强大的分布式存储能力,它能够将海量的数据分散存储在多个节点上,实现了数据的高可靠性和可扩展性,通过 Hadoop 的分布式文件系统(HDFS),数据可以被安全地存储和访问,即使个别节点出现故障,也不会导致数据的丢失。
Spark 则以其出色的内存计算能力脱颖而出,它能够将数据加载到内存中进行快速处理,大大提高了数据处理的速度和效率,尤其是在处理迭代计算和实时数据处理方面,Spark 表现得极为出色。
Hadoop 具有良好的批处理能力,适合处理大规模的离线数据,对于那些需要长时间运行的大规模数据处理任务,Hadoop 能够稳定地完成工作,并且能够处理各种格式的数据,具有很强的通用性。
而 Spark 不仅在内存计算方面表现出色,还提供了丰富的高级 API,使得数据处理的编程变得更加简单和高效,开发人员可以使用 Spark 的 API 轻松地构建复杂的数据处理流程。
Hadoop 生态系统非常丰富,包含了众多的组件和工具,如 Hive、Pig 等,能够满足不同的数据分析需求,Spark 也在不断发展和完善其生态系统,与其他技术的集成也越来越紧密。
Hadoop 和 Spark 虽然在优势上有所不同,但在实际应用中,往往会根据具体的业务需求和场景来选择使用,它们共同为大数据处理和分析提供了强大的支持,推动了大数据技术的不断发展和创新。
文章参考来源:大数据技术相关书籍及权威技术论坛。
