解析 PHP 网页爬虫应对 HTTP 状态码的秘籍
在网络世界中,PHP 网页爬虫处理 HTTP 状态码是至关重要的一环,HTTP 状态码反映了服务器与客户端之间的交互情况,对于爬虫来说,准确理解和处理这些状态码能够极大地提高数据采集的效率和质量。
HTTP 状态码种类繁多,常见的有 200(成功)、404(未找到)、500(内部服务器错误)等,对于 PHP 网页爬虫而言,不同的状态码需要采取不同的处理策略。
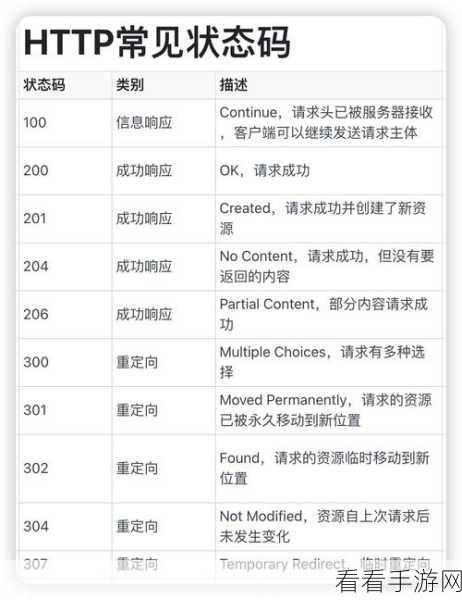
当遇到 200 状态码时,意味着请求成功,爬虫可以顺利获取到所需的数据,但这并不意味着就可以高枕无忧,还需要对获取的数据进行有效性和完整性的检查。
而碰到 404 状态码,则表示请求的页面不存在,在这种情况下,爬虫需要记录下来,避免后续重复无效的请求,节省资源和时间。
如果遇到 500 内部服务器错误,可能是服务器端出现了问题,爬虫不能简单地放弃,而是可以设置一个重试机制,在适当的时间间隔后再次尝试请求。
还有一些其他的状态码,如 301(永久重定向)、302(临时重定向)等,也需要爬虫根据具体情况进行相应的处理。
熟练掌握 PHP 网页爬虫处理 HTTP 状态码的技巧,能够让爬虫在网络数据采集的道路上更加顺畅,为后续的数据分析和应用提供有力的支持。
文章参考来源:相关技术论坛及专业书籍。
仅供参考,您可以根据实际需求进行调整和修改。
