破解 Hadoop 与 Spark 常见难题的终极指南
Hadoop 和 Spark 作为大数据领域的重要技术,在实际应用中常常会遇到各种问题,这篇攻略将带您深入了解并解决这些常见问题。
Hadoop 与 Spark 常见问题的解决至关重要,在大数据处理中,它们的稳定运行直接影响着工作效率和成果质量,无论是数据存储、计算性能还是资源分配,任何一个环节出现问题都可能导致整个系统的卡顿甚至崩溃。
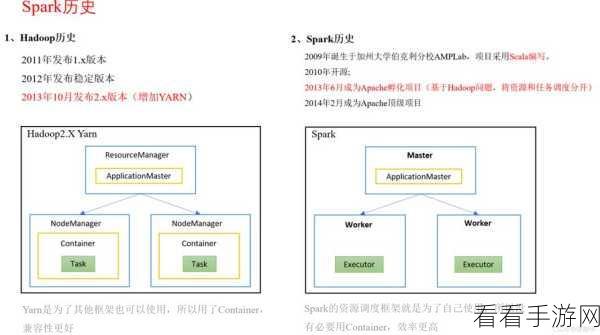
想要解决 Hadoop 与 Spark 的常见问题,我们得先搞清楚问题的类型,常见的有数据倾斜问题,这可能导致某些节点负载过高,影响整体处理速度;还有内存不足的情况,可能使任务无法正常完成。
对于数据倾斜问题,我们可以通过优化数据分布、使用合适的分区策略来解决,根据关键列进行更合理的分区,使得数据在各个节点上分布更均匀。
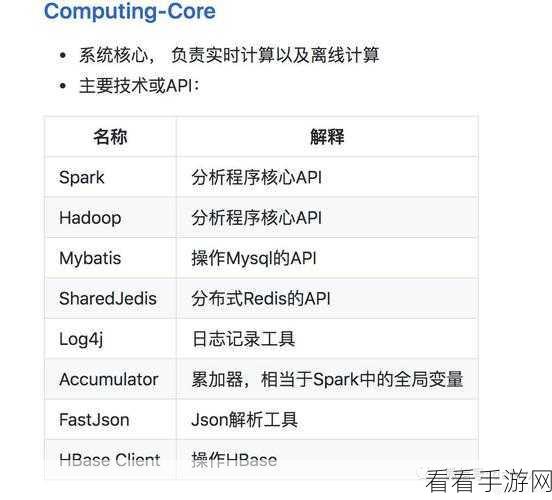
而内存不足的情况,则可以通过调整内存配置参数来改善,也要注意任务的并行度设置,避免资源浪费。
网络延迟和节点故障也是需要关注的点,及时监测网络状态,做好节点的备份和恢复工作,能够有效减少问题带来的影响。
解决 Hadoop 与 Spark 的常见问题需要我们综合考虑多个方面,不断尝试和优化,才能确保系统的稳定高效运行。
参考来源:相关技术论坛及专业书籍。
仅供参考,您可以根据实际需求进行调整和修改。
