大数据时代,Hadoop 与 Spark 的完美协同之道
在当今数字化的时代,数据处理和分析成为了企业和组织发展的关键,Hadoop 和 Spark 作为大数据处理领域的重要技术,它们的协同工作能够为数据处理带来更高的效率和更强大的功能,Hadoop 和 Spark 究竟是如何协同工作的呢?
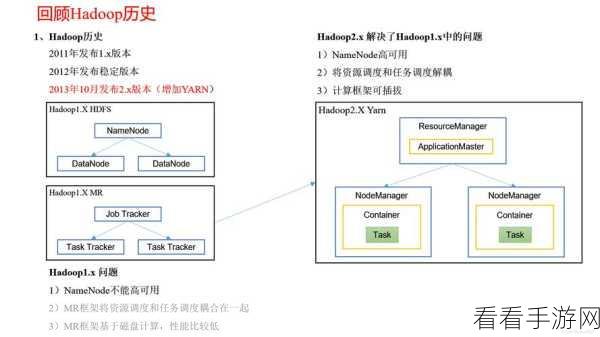
Hadoop 是一个分布式系统基础架构,它能够存储和处理大规模的数据,其核心组件包括 HDFS(Hadoop 分布式文件系统)和 MapReduce 计算模型,HDFS 提供了高可靠性和高扩展性的数据存储,而 MapReduce 则用于大规模数据的并行处理。
Spark 则是一种快速、通用的大数据计算框架,它基于内存计算,具有高效的执行速度和丰富的高级 API,与 Hadoop 的 MapReduce 相比,Spark 在处理迭代计算和交互式查询方面具有明显的优势。
Hadoop 和 Spark 的协同工作主要体现在数据存储和计算任务的分配上,Hadoop 的 HDFS 可以作为数据的存储基础,为 Spark 提供数据来源,而 Spark 可以利用其高效的计算能力,对存储在 HDFS 中的数据进行快速处理和分析。
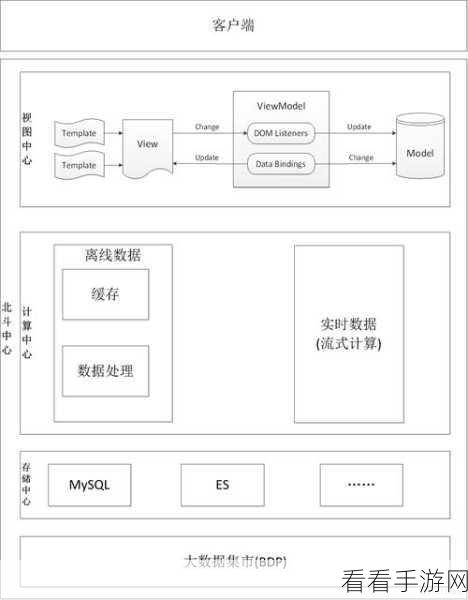
在实际应用中,Hadoop 和 Spark 的协同工作可以通过多种方式实现,可以将 Hadoop 用于数据的批量处理和初始存储,然后使用 Spark 进行实时分析和数据挖掘,还可以利用 Hadoop 的 YARN 资源管理器来统一管理 Hadoop 和 Spark 的计算资源,实现资源的高效利用。
Hadoop 和 Spark 的协同工作为大数据处理提供了更强大的工具和更灵活的解决方案,通过合理的配置和应用,能够充分发挥它们各自的优势,满足不同业务场景的需求。
文章参考来源:大数据相关技术书籍和专业论坛的讨论。
