大数据领域对决,Hadoop 与 Spark 谁更胜一筹?
在当今的大数据时代,Hadoop 和 Spark 是两个备受关注的技术框架,它们都在数据处理和分析方面发挥着重要作用,但究竟哪一个更高效呢?这是许多数据从业者和研究者常常探讨的问题。
Hadoop 是一个分布式系统基础架构,具有高度的容错性和扩展性,它擅长处理大规模的离线数据,通过分布式存储和并行计算,能够处理 PB 级别的数据量,Hadoop 的计算模型相对较为简单,处理速度在某些情况下可能不尽如人意。
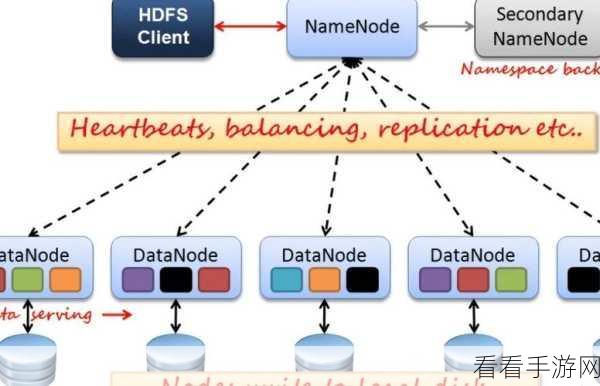
Spark 则是基于内存计算的大数据处理框架,其性能在很多场景下表现出色,它能够快速地进行迭代计算和实时数据处理,对于需要频繁交互和快速响应的应用场景具有明显优势,但 Spark 对于资源的消耗相对较高,在大规模数据处理时可能会面临一些挑战。
要比较 Hadoop 和 Spark 的效率,需要考虑多个因素,数据的特点是一个关键因素,如果数据量巨大且处理逻辑相对简单,Hadoop 可能更适合;而对于数据交互频繁、计算逻辑复杂的场景,Spark 往往能展现出更好的性能。
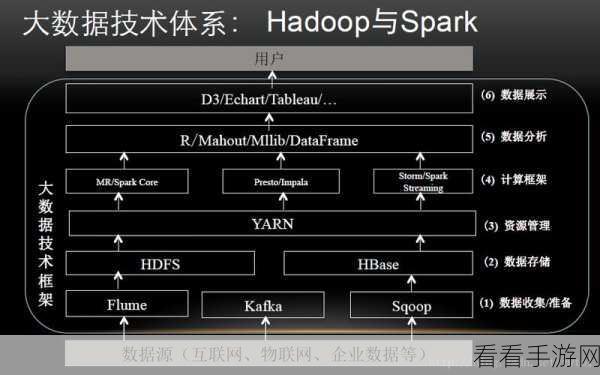
应用场景也是影响选择的重要因素,在离线数据分析和大规模数据存储方面,Hadoop 具有传统优势;而在实时数据处理、机器学习和流处理等领域,Spark 则更具竞争力。
技术团队的熟悉程度和资源配置也会对选择产生影响,如果团队对 Hadoop 技术积累深厚,那么在实际应用中可能更倾向于使用 Hadoop;反之,如果团队对 Spark 有更多的经验和掌握,可能会优先考虑 Spark。
Hadoop 和 Spark 各有优劣,不能简单地判定哪一个更高效,在实际应用中,需要根据具体的业务需求、数据特点、技术团队情况等多方面因素进行综合考量,从而选择最适合的大数据处理框架,以实现高效的数据处理和分析。
文章参考来源:相关大数据技术研究资料及行业实践经验。
