大数据处理神器,Hadoop 与 Spark 究竟该如何抉择?
在当今数字化时代,大数据技术的应用愈发广泛,而在众多大数据处理工具中,Hadoop 和 Spark 备受关注,但对于许多开发者和企业来说,如何在它们之间做出明智的选择,成为了一个关键问题。
Hadoop 作为大数据处理领域的先驱,具有出色的分布式存储和处理能力,它能够处理海量的数据,并以其稳定性和可靠性著称,Hadoop 的处理速度相对较慢,在一些对实时性要求较高的场景中可能表现不佳。
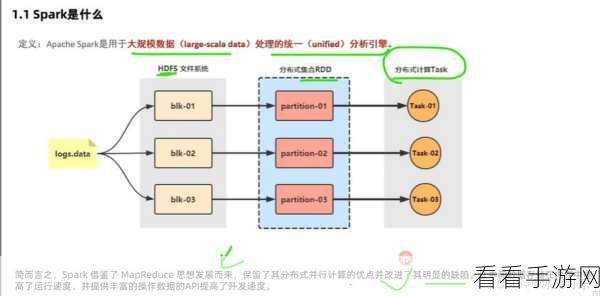
Spark 则是后起之秀,它在处理速度上有着显著的优势,Spark 基于内存计算,能够大大提高数据处理的效率,尤其适合需要快速迭代和实时分析的业务场景,但 Spark 对于资源的要求相对较高,需要更强大的硬件支持。
如何根据具体需求来选择 Hadoop 和 Spark 呢?需要考虑数据量的大小,如果数据量极大,Hadoop 的分布式存储优势能够发挥作用;若数据量适中且对处理速度有较高要求,Spark 可能是更好的选择,要考虑业务的实时性需求,对于实时分析和快速响应要求高的业务,Spark 更能满足需求;而对于一些对实时性要求不那么迫切的任务,Hadoop 可以提供稳定可靠的处理。
团队的技术能力和资源配置也是重要的因素,如果团队对 Hadoop 技术较为熟悉,并且有足够的资源进行优化和维护,那么选择 Hadoop 可能更为顺畅,反之,如果团队具备 Spark 开发的能力和经验,并且能够提供相应的硬件资源,Spark 或许是更优的选项。
选择 Hadoop 还是 Spark 并非绝对,需要综合考虑数据量、实时性需求、团队技术能力和资源配置等多方面因素,只有在充分了解自身需求和技术特点的基础上,才能做出最适合的选择,从而为大数据处理和分析提供有力的支持。
文章参考来源:大数据技术相关专业书籍及行业研究报告。
