大数据领域,Hadoop 与 Spark 的深度差异剖析
在当今的大数据时代,Hadoop 和 Spark 是两个备受关注的技术框架,它们在处理大规模数据方面都有着重要的地位,但也存在着显著的区别。
Hadoop 是一个分布式系统基础架构,主要由 HDFS(分布式文件系统)和 MapReduce(分布式计算模型)组成,其特点在于能够处理海量数据的存储和批处理任务,具有良好的稳定性和容错性,Hadoop 的 MapReduce 计算模型在处理复杂的迭代计算和实时性要求较高的任务时,表现相对不足。

Spark 则是基于内存计算的大数据处理框架,它在处理速度上有着明显的优势,尤其是对于需要多次迭代计算和实时性要求较高的任务,Spark 支持多种编程语言,提供了丰富的 API,使得开发人员能够更加便捷地进行数据处理和分析。
Hadoop 和 Spark 的具体区别究竟体现在哪些方面呢?
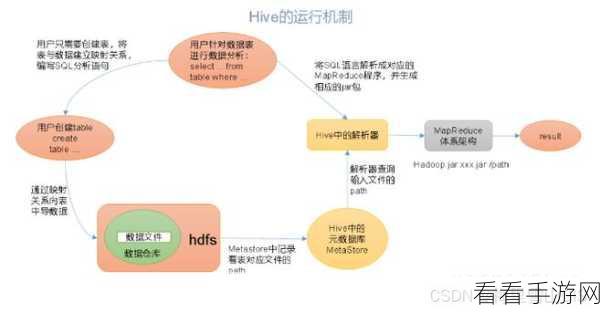
从数据处理方式来看,Hadoop 的 MapReduce 是基于磁盘的计算,每次计算都需要将数据从磁盘读取和写入,导致处理速度相对较慢,而 Spark 采用了基于内存的计算模式,能够将数据缓存在内存中,大大提高了数据处理的效率。
在资源管理方面,Hadoop 依赖于 YARN 进行资源管理和调度,而 Spark 可以在 YARN 上运行,也支持自身的独立部署模式。
在应用场景上,Hadoop 更适合处理大规模的离线数据批处理任务,如数据仓库的构建、日志分析等,Spark 则适用于实时数据处理、机器学习、图计算等需要快速迭代和实时响应的场景。
Hadoop 和 Spark 各有优劣,用户应根据具体的业务需求和场景来选择合适的技术框架,在实际应用中,也可以将两者结合使用,充分发挥它们的优势,以实现更高效的数据处理和分析。
文章参考来源:大数据相关技术文档和专业书籍。
