大数据新手必知,Hadoop 与 Spark 谁是入门首选?
对于想要踏入大数据领域的初学者来说,Hadoop 和 Spark 无疑是两个备受关注的技术,但究竟哪一个更适合作为入门之选呢?这是许多新手面临的困惑。
Hadoop 是一个分布式系统基础架构,具有强大的数据存储和处理能力,它的核心组件包括 HDFS(分布式文件系统)和 MapReduce(分布式计算模型),Hadoop 适合处理大规模的静态数据,对于数据的批处理有着出色的表现,其优势在于稳定性和成熟度,经过多年的发展和实践,在处理海量数据方面有着可靠的性能。
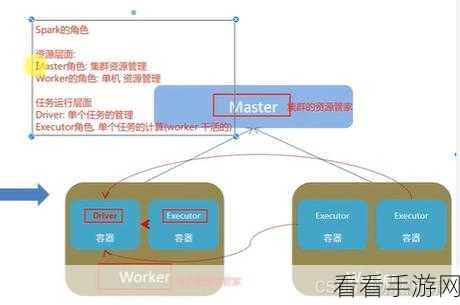
Spark 则是一种快速、通用的大数据计算框架,它基于内存计算,大大提高了数据处理的速度,Spark 支持多种数据处理方式,如批处理、流处理、机器学习等,与 Hadoop 相比,Spark 在处理实时数据和迭代计算方面更具优势,能够提供更高效的数据分析和挖掘能力。
对于初学者来说,如何选择呢?如果您对数据的稳定性和大规模批处理有较高需求,Hadoop 可能是一个不错的起点,它能让您深入理解大数据处理的基本原理和架构,如果您希望快速上手并进行高效的数据分析,尤其是在实时数据处理方面有兴趣,Spark 或许更适合您。

Hadoop 和 Spark 各有千秋,初学者应根据自己的兴趣和需求来选择,无论选择哪一个,都需要不断学习和实践,才能在大数据领域有所建树。
参考来源:大数据技术相关书籍及权威技术论坛。
