探索大数据,Hadoop 与 Spark 生态系统的奥秘
大数据时代,Hadoop 和 Spark 成为了引领技术潮流的关键力量,它们所构建的生态系统,为数据处理和分析带来了前所未有的变革。
Hadoop 作为大数据处理的奠基者,以其分布式存储和并行计算的能力,为海量数据的处理提供了坚实的基础,其核心组件包括 HDFS(Hadoop 分布式文件系统)和 MapReduce 计算框架,HDFS 能够将数据分散存储在多个节点上,实现了数据的高可靠性和可扩展性;MapReduce 则通过将复杂的计算任务分解为多个小任务,并在多个节点上并行执行,大大提高了数据处理的效率。
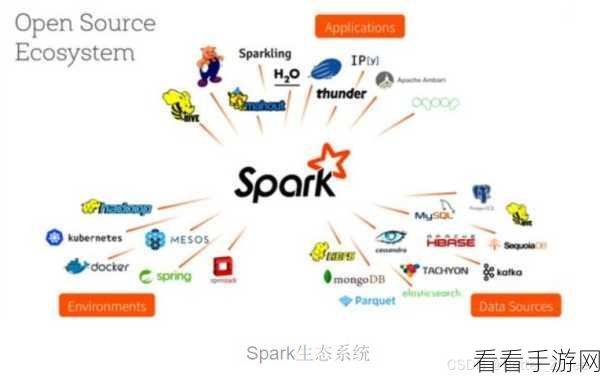
Spark 则是在 Hadoop 的基础上发展起来的新一代大数据处理框架,它具有更快的处理速度、更灵活的编程模型和更丰富的高级功能,Spark 的核心优势在于其基于内存的计算模式,能够显著减少数据的读写次数,从而大幅提升计算性能,Spark 还提供了丰富的 API,支持多种编程语言,如 Java、Scala、Python 等,使得开发者能够更加便捷地进行数据处理和分析任务。
在实际应用中,Hadoop 和 Spark 通常会结合使用,以充分发挥各自的优势,对于大规模的历史数据存储和批处理任务,可以使用 Hadoop 进行处理;而对于实时性要求较高的数据分析和流处理任务,则可以借助 Spark 的强大功能来实现。
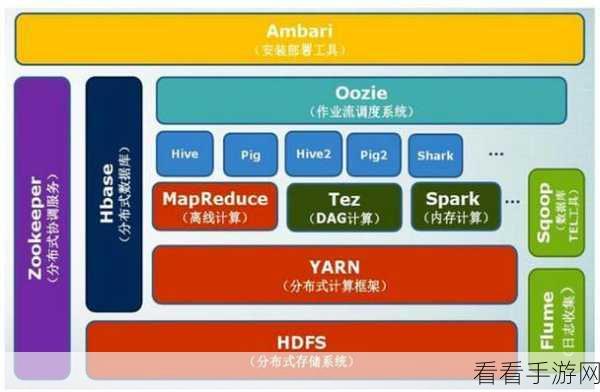
Hadoop 和 Spark 的生态系统为大数据处理和分析提供了强大的支持,它们的不断发展和创新,将为我们开启更多数据驱动的可能性。
文章参考来源:相关技术书籍及网络技术论坛。
