大数据 Hadoop 与 Spark 编程难度大揭秘
在当今数字化时代,大数据技术的重要性日益凸显,Hadoop 和 Spark 作为大数据处理领域的两大核心框架,其编程难度一直备受关注。
Hadoop 是一个分布式系统基础架构,具有强大的数据存储和处理能力,其编程模式相对较为复杂,需要开发者对分布式计算的原理有深入理解,对于初学者来说,配置和部署 Hadoop 集群就可能是一项艰巨的任务,Hadoop 的编程接口相对底层,需要开发者处理大量的细节,这无疑增加了编程的难度。
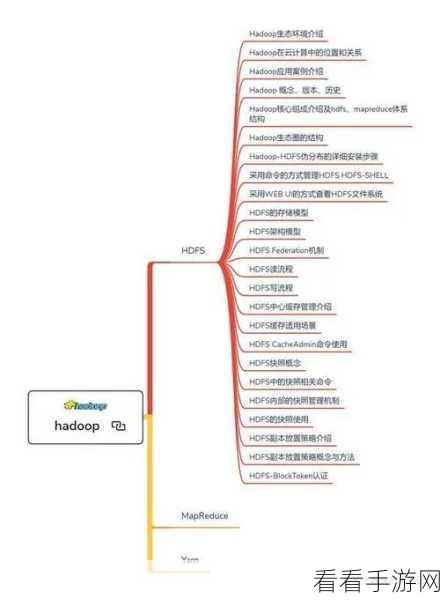
Spark 则是一种快速、通用的大数据计算框架,它在性能和易用性方面有了显著的提升,与 Hadoop 相比,Spark 的编程模型更加高级和灵活,支持多种编程语言,并且提供了丰富的 API 接口,这使得开发者能够更高效地编写代码来处理数据,但 Spark 也并非毫无挑战,其复杂的优化参数和内存管理机制,如果处理不当,可能会导致性能下降。
要掌握 Hadoop 和 Spark 的编程,首先需要扎实的编程基础,尤其是对 Java 或 Python 等语言的熟练掌握,深入学习分布式计算的理论知识是必不可少的,这将有助于理解数据在分布式环境中的存储和处理方式,通过实际项目的实践来积累经验也是关键。
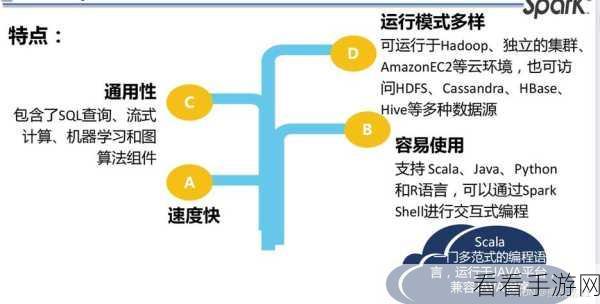
Hadoop 和 Spark 的编程难度各有特点,选择适合自己需求和技术水平的框架,并不断学习和实践,才能在大数据领域游刃有余。
文章参考来源:相关技术论坛及专业书籍。
