探秘 Hive Analyze 处理大数据的神奇之道
Hive Analyze 是处理大数据的重要工具,它拥有强大的功能和复杂的操作技巧。
想要深入理解 Hive Analyze 如何处理大数据,就得先明白其基本原理,Hive Analyze 基于分布式计算框架,能够高效地对海量数据进行分析和处理,它通过将大规模的数据分割成多个小部分,并在多个节点上并行处理,从而大大提高了数据处理的速度和效率。

在实际应用中,Hive Analyze 有着多种处理策略,优化查询语句是关键的一环,合理的查询语句可以显著减少数据处理的时间和资源消耗,避免使用不必要的全表扫描,而是通过索引和分区来提高查询效率。
数据存储的选择也至关重要,Hive 支持多种数据存储格式,如 TextFile、ORC、Parquet 等,不同的存储格式在数据压缩率、读取效率等方面存在差异,根据数据的特点和处理需求,选择合适的存储格式能有效提升大数据处理的性能。
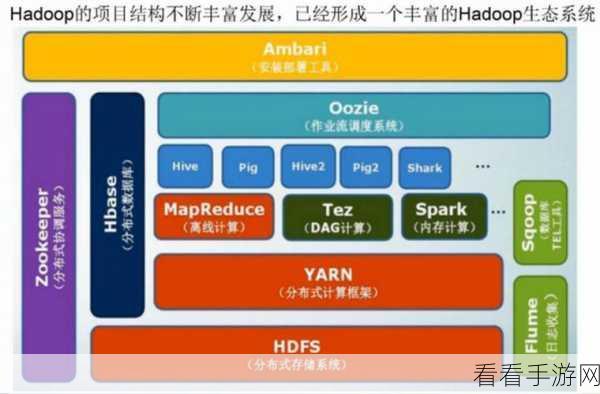
资源配置也是影响 Hive Analyze 处理大数据效果的重要因素,合理分配内存、CPU 等资源,可以确保处理任务能够顺利进行,避免因资源不足导致的处理中断或延迟。
掌握 Hive Analyze 处理大数据的技巧需要综合考虑多个方面,包括原理理解、查询优化、存储选择和资源配置等,只有在这些方面不断探索和实践,才能充分发挥 Hive Analyze 的强大功能,高效处理大数据,为数据分析和决策提供有力支持。
文章参考来源:相关技术文档及行业研究报告。
