掌握 Spark 大数据处理的实战秘籍
Spark 大数据处理技术在当今的数字化时代具有举足轻重的地位,它为企业和开发者提供了强大的工具,以高效处理海量数据。
Spark 之所以备受青睐,是因为其具备出色的性能和可扩展性,它能够在短时间内处理大规模的数据,并且能够轻松应对数据量的增长和复杂的计算需求。

在实际应用中,要实现 Spark 大数据处理的最佳效果,需要遵循一系列的原则和策略,数据的预处理至关重要,确保数据的质量和格式规范,能够为后续的处理节省大量的时间和资源,合理配置资源也是关键,根据数据量和计算任务的特点,调整内存、CPU 等资源的分配,以达到最优的性能,选择合适的算法和数据结构能够显著提高处理效率。
为了更好地理解 Spark 大数据处理的最佳实践,我们可以通过一些实际的案例来进行分析,某电商企业利用 Spark 对用户的购买行为数据进行分析,通过优化数据预处理和算法选择,成功提高了推荐系统的准确性,从而提升了用户的购买转化率。
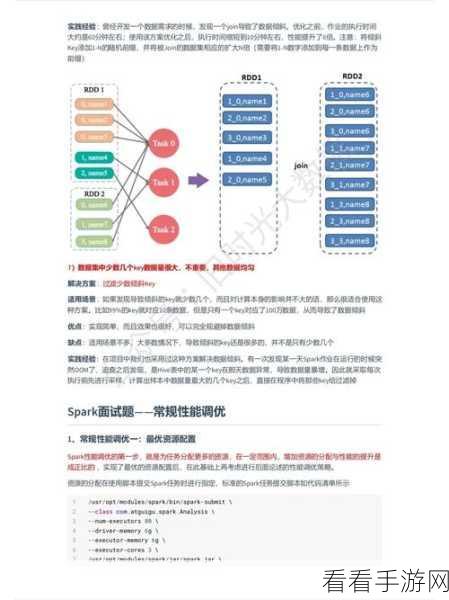
掌握 Spark 大数据处理的最佳实践并非一蹴而就,需要不断地学习和实践,只有深入了解其原理和特点,并结合实际的业务需求,才能充分发挥 Spark 的优势,为企业创造更大的价值。
文章参考来源:相关技术论坛及专业书籍。
