深度剖析,Spark 大数据处理中的数据倾斜难题
在大数据处理领域,Spark 凭借其出色的性能和广泛的应用场景,成为了众多开发者和企业的首选,在使用 Spark 进行数据处理时,数据倾斜问题常常成为困扰大家的一个难题。
数据倾斜指的是在分布式计算中,某些节点承担了过多的数据处理任务,而其他节点处理的数据量相对较少,从而导致整个计算任务的性能下降,这种不平衡的分配会极大地影响 Spark 作业的执行效率,延长处理时间,甚至可能导致任务失败。
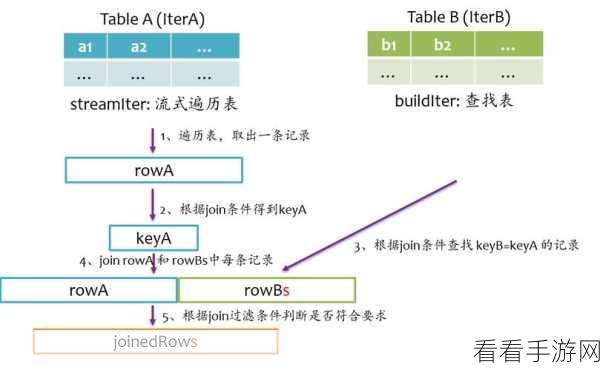
造成 Spark 数据倾斜的原因有哪些呢?常见的原因包括数据分布不均匀、某些 key 值的出现频率过高、业务逻辑设计不合理等,在数据预处理阶段,如果没有对数据进行合理的分区和分布,就容易导致部分分区的数据量过大,从而引发数据倾斜。
要解决 Spark 数据倾斜问题,可以采取多种策略,一种有效的方法是对数据进行预处理,通过采样分析找出可能导致倾斜的 key 值,并对其进行特殊处理,可以将这些 key 值单独提取出来进行处理,或者对其进行打散重新分布。
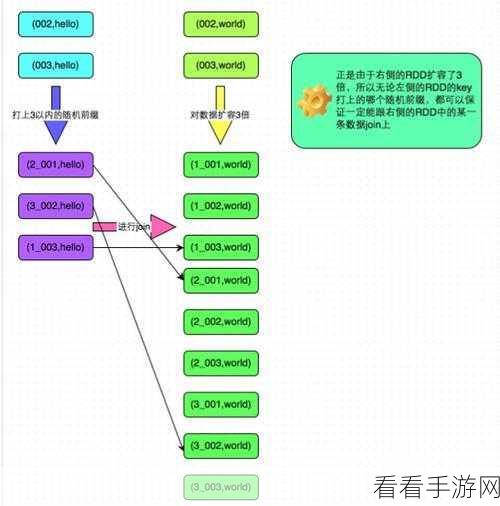
另一种解决方法是调整业务逻辑,在设计计算逻辑时,尽量避免对某些热点 key 值进行过度集中的操作,通过合理的分散和均衡,减少数据倾斜的可能性。
还可以通过调整 Spark 的配置参数来优化数据倾斜问题,增加并行度、调整内存分配等,以提高系统的处理能力和资源利用率。
解决 Spark 大数据处理中的数据倾斜问题需要综合考虑数据特点、业务逻辑和系统配置等多方面因素,采取针对性的措施,才能有效地提高数据处理的效率和性能。
参考来源:相关技术文档及大数据处理领域的研究成果。
