探秘 Spark 大数据处理的内存计算魔法
Spark 大数据处理中的内存计算是一项具有变革性的技术,它能够极大地提升数据处理的效率和速度,为各种应用场景带来全新的可能。
内存计算之所以如此重要,是因为传统的数据处理方式在面对海量数据时往往显得力不从心,而 Spark 的内存计算模式则打破了这一限制,通过将数据直接存储在内存中进行计算,大大减少了数据的读取和写入时间。

在实际应用中,Spark 内存计算展现出了诸多优势,它能够快速处理实时数据,让企业能够及时做出决策,对于复杂的数据分析任务,如机器学习和数据挖掘,内存计算能够提供强大的算力支持,使得这些任务能够在更短的时间内完成。
要充分发挥 Spark 内存计算的效能,还需要合理配置资源,这包括内存的分配、CPU 的使用以及网络带宽的优化等方面,只有在各个环节都进行精心的调整和优化,才能确保系统的稳定运行和高效处理。
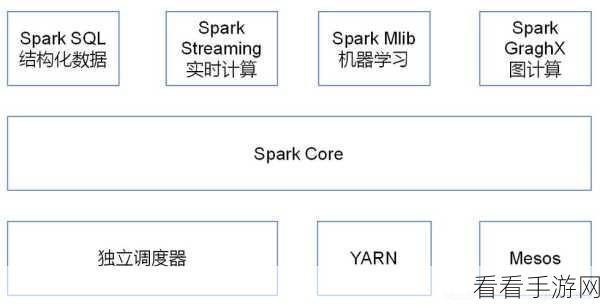
数据的预处理和清洗也是至关重要的环节,在将数据导入内存计算之前,对数据进行筛选、去重和格式化等操作,可以减少不必要的计算量,提高处理效率。
Spark 大数据处理的内存计算是当今数据处理领域的一颗璀璨明星,掌握并合理运用这一技术,将为企业和开发者带来巨大的价值和竞争优势。
文章参考来源:相关技术文档及行业研究报告。
