Spark 大数据处理性能优化秘籍大揭秘
Spark 作为大数据处理领域的重要工具,其性能优化至关重要,在当今数字化时代,数据量呈爆炸式增长,如何高效地处理和分析这些数据成为了企业和开发者面临的关键挑战,而 Spark 的性能优化则是解决这一问题的核心所在。
Spark 性能优化涉及多个方面,数据存储和读取的优化是基础,合理选择数据存储格式,如 Parquet 或 ORC,能够显著提高数据读取的效率,对数据分区的精心设计也能减少数据处理时的 I/O 开销。
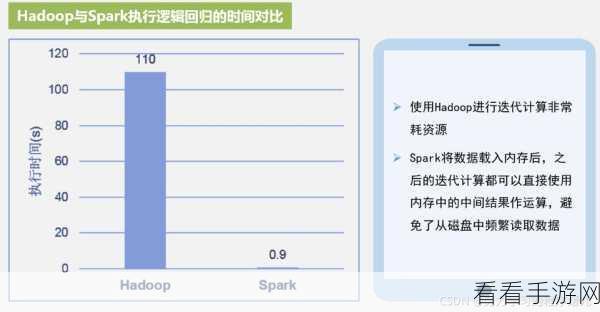
在计算资源的分配和利用方面,需要根据任务的特点和集群的规模进行合理配置,调整内存分配参数,确保 executor 内存充足,以避免频繁的内存溢出,合理设置并行度,充分利用集群的计算能力,提升任务的执行速度。
代码优化也是提升 Spark 性能的重要环节,避免不必要的操作,如重复计算和数据转换,能够减少计算量,优化数据结构和算法,选择合适的函数和操作符,能够提高代码的执行效率。
对于 Spark 作业的调优,监控和分析是关键,通过监控系统指标,如 CPU 利用率、内存使用情况、网络 I/O 等,及时发现性能瓶颈,利用 Spark 的 Web UI 和日志分析工具,深入了解作业的执行情况,从而针对性地进行优化。
要实现 Spark 大数据处理的性能优化,需要综合考虑数据存储、计算资源、代码和作业调优等多个方面,不断探索和实践,才能在大数据处理的浪潮中脱颖而出。
参考来源:大数据处理相关技术文档及实践经验总结
