大数据 Spark 与 Hadoop 的深度较量,谁更胜一筹?
在当今的大数据领域,Spark 和 Hadoop 无疑是两个备受关注的技术框架,它们各自有着独特的特点和优势,也在不同的应用场景中发挥着重要作用,究竟谁更出色呢?
Spark 以其出色的内存计算能力而闻名,它能够在内存中快速处理和分析数据,大大提高了数据处理的速度和效率,相比之下,Hadoop 则更侧重于大规模数据的存储和分布式处理。
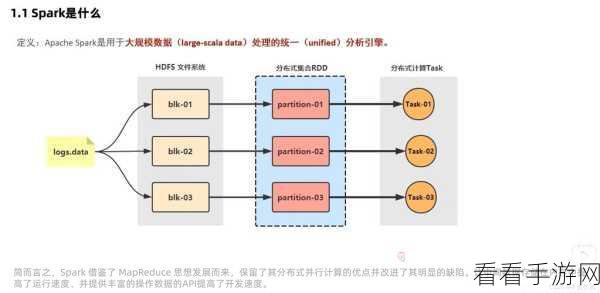
Hadoop 的 MapReduce 计算模型虽然在处理大规模数据时表现稳定,但在处理复杂的迭代计算和实时性要求较高的任务时,就显得有些力不从心,而 Spark 凭借其丰富的高级 API 和优化的执行引擎,能够轻松应对这些挑战。
Spark 还具有良好的兼容性和扩展性,它可以与多种数据源和存储系统进行集成,如 HDFS、HBase 等,为用户提供了更加灵活和便捷的数据处理方案。
Hadoop 也并非一无是处,其在数据存储和管理方面的成熟性和稳定性是经过多年实践检验的,对于一些对计算资源要求不高、数据规模较大的场景,Hadoop 仍然是一个可靠的选择。
Spark 和 Hadoop 各有千秋,在实际应用中,用户应根据具体的业务需求和场景来选择合适的技术框架,以达到最佳的数据处理效果。
参考来源:大数据相关技术论坛及权威研究报告。
中心句总结:
1、在当今的大数据领域,Spark 和 Hadoop 备受关注,各自有特点和优势。
2、Spark 内存计算能力出色,Hadoop 侧重大规模数据存储和分布式处理。
3、Spark 在处理复杂迭代和实时任务方面有优势,且兼容性扩展性良好。
4、Hadoop 在数据存储管理方面成熟稳定,在特定场景仍是可靠选择。
5、实际应用中应根据需求和场景选择合适的技术框架以达最佳效果。
